Hello!
I’m pretty new to VVVV. I’ve been researching how I could get images from an HTML source and found some posts that have pointed me in the right direction, but didn’t cut it for me. I’m just getting a black renderer.
I want to be able to get images from various news websites, show them in quads and randomize the order. And later create patterns using these images. But for now I need tackle the first issue.
Here are some posts that have given me an insight into how this might work using HTTP (Network Get String Legacy) and RegExpr:
FlickrAccessWithXPath.v4p (18.7 KB)
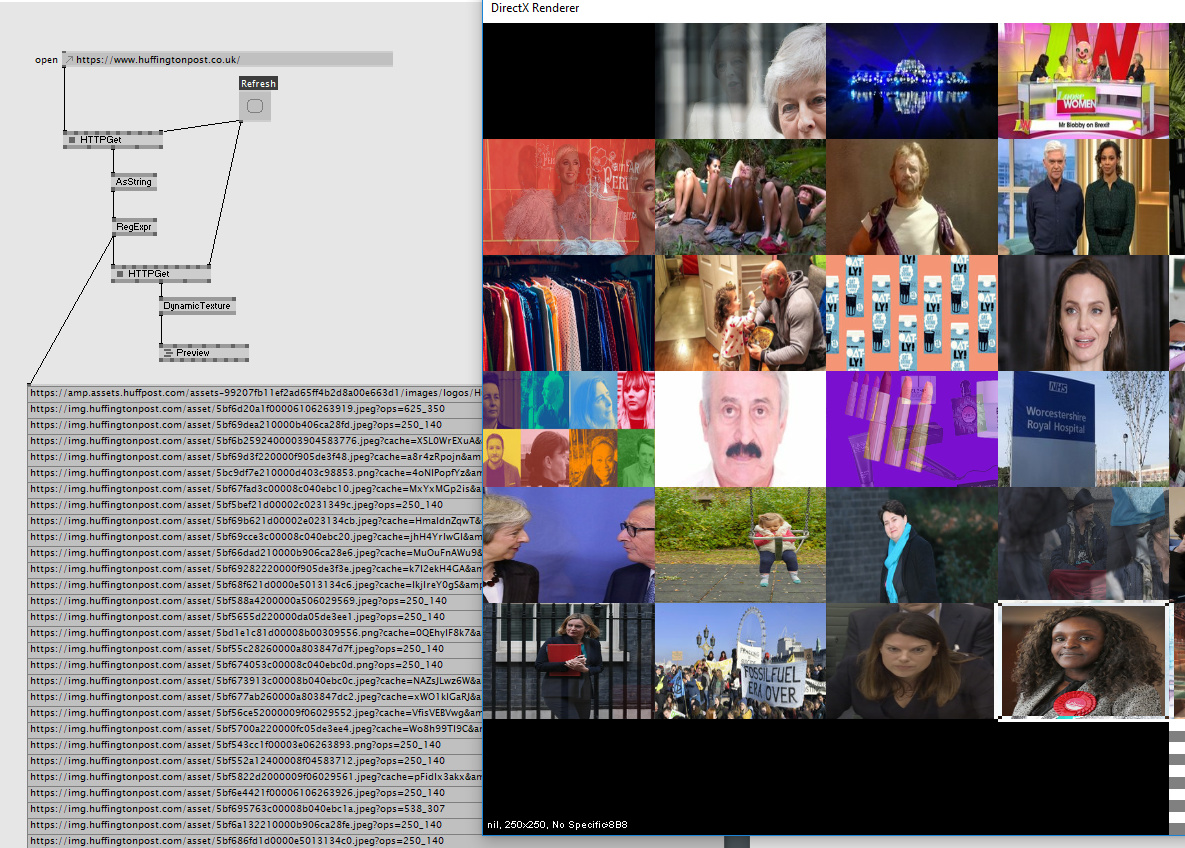
Here’s one I’ve been experimenting with. It should be able to search for images as well, but gives me no results.
Thanks
Is this some old example you found in the forum? The xpath query is wrong altogether regarding the document you are loading. Mybe just outdated because flickr changed things over the years. Scraping websites is no fun and likely to break on any minor change of the site. You need to examine the html source and form a query that matches what you are after. If you are not very familiar with html and xpath queries this might be quite a journey.
Also flickr seems to do a lot of dynamic loading and obfuscation with java script. For example you might get the images from the search overview quite easy but if you want to get the full res picture you wont find the url in the source code until you click and zoom. Probably there will be similar hassle with other modern sites like the google image search for examle. They just load things dynamically with code to be more efficient.
Thanks for the quick response. Yes this is an example I found on the forum - it’s close to what I have intended to do. I want to use images from the front pages of news websites like https://www.huffingtonpost.co.uk/
“If you are not very familiar with html and xpath queries this might be quite a journey.”
I’m guessing this applies to most sites. Even if I didn’t need it to load search results.
“…but if you want to get the full res picture you wont find the url in the source code until you click and zoom.”
I’m not too worried about getting full res pictures.
I made a little example for you with the regex node as it seemed the easiest. I have not much clue about regular expressions though, it is just a snippet i found online that actually worked with the v4 regex node. It extracts strings from the html that match an img tag and have a src attribute or smth like that. It certainly can be improved to filter just for jpg or png and cut off any additional parameters in the url. It is quite rough but it works and you should get an idea. Anyway, note though that parsing html with regex is regarded as bad and prone to errors.
It’s awesome that you got it working! I will test it out.
“It extracts strings from the html that match an img tag and have a src attribute or smth like that.”
That’s exactly what I need.
Tnx
@tonfilm: As HTML is not quite XML they tend to choke on malformed or HTML specific things.
For example they will error when the document contains tags like <script async src="…>
So async will be flagged as malformed attribute and there it stops.
that’s true. in this case, if you only want to find url’s you can use a regex match for url’s because the surrounding html structure doesn’t matter much.