Efforts are going in the direction of bringing native support for Microsoft’s Kinect v2 to vl, ie making it usable also in vvvv gamma.
We’re assuming that the set of nodes for Kinect2 by @vux available for vvvv beta now is the desired goal.
The purpose of this WIP is to open a discussion which enables future users of this library to bring their thoughts, usecases, ideas and previous experiences forth to be taken into account during this development process.
If we don’t hear from you, here is the set of nodes that we’ll initially be concentrating on:
Kinect2: Represents the kinect device. Allows for general configuration for the device and the information it provides
RGB (Image): Color camera image
Depth (Image): Depth sensor data as an 16-bit image
IR (Image): Infrared camera image
DepthToRGB (Image): UV map matching depth to RGB
RGBToDepth (Image): UV map matching RGB to depth
Skeleton: Returns skeleton data for each tracked user
BodyIndex(Image): Returns colored version of player (body index image)
CameraIntrinsics: Provides FocalLength, PrincipalPoint and RadialDistortion information for the provided Camera Intrinsics
If you have any ideas, comments or in general anything to add to this, please do.
I’ve used the faceHD tracking before, and the fusion looked interesting but never used for more than a look, maybe that would be interesting with more access to the pipeline (not even sure thats in the recent versions or not?)
@catweasel interesting point, both of those features are packed up in a single node (each) in DX11, but maybe splitting them into a few more nodes allowing more configuration and control would be a good idea. Do you have any suggestions in particular?
Soo, we are trying to figure out how to handle (if at all) the Frame Index output pin found in all stream nodes (RGB, Depth, IR, etc.) in DX11. As far as I have managed to understand it is mainly there for synchronization purposes.
Has anyone ever needed/used this pin? Is it important for us to include it in the new version or not? Please post your thoughts on this.
After struggling for a few days with bugs related to the lifecycle of the KinectSensor and various streams as reported here, and only thanks to the help of @Elias, the decision was to change the design of the nodeset in a way that will better handle the invocations of creations and disposals of the different objects involved.
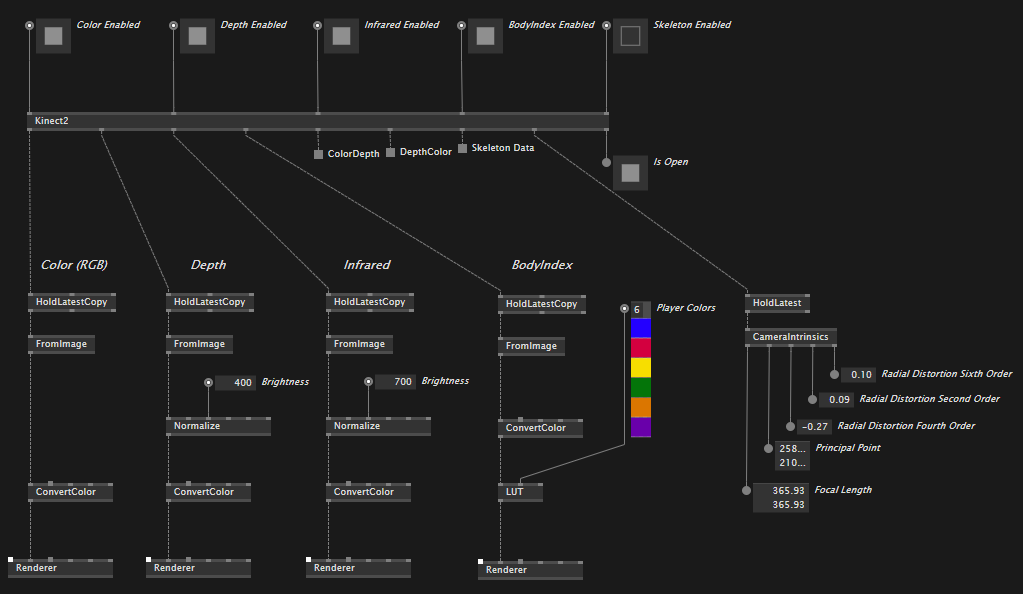
To sum it up quickly, instead of having one Kinect2 node as a source, and a consumer node per stream (RGB, Depth, etc.) the new proposal has just a single Kinect2 node with an output for each of the existing streams.
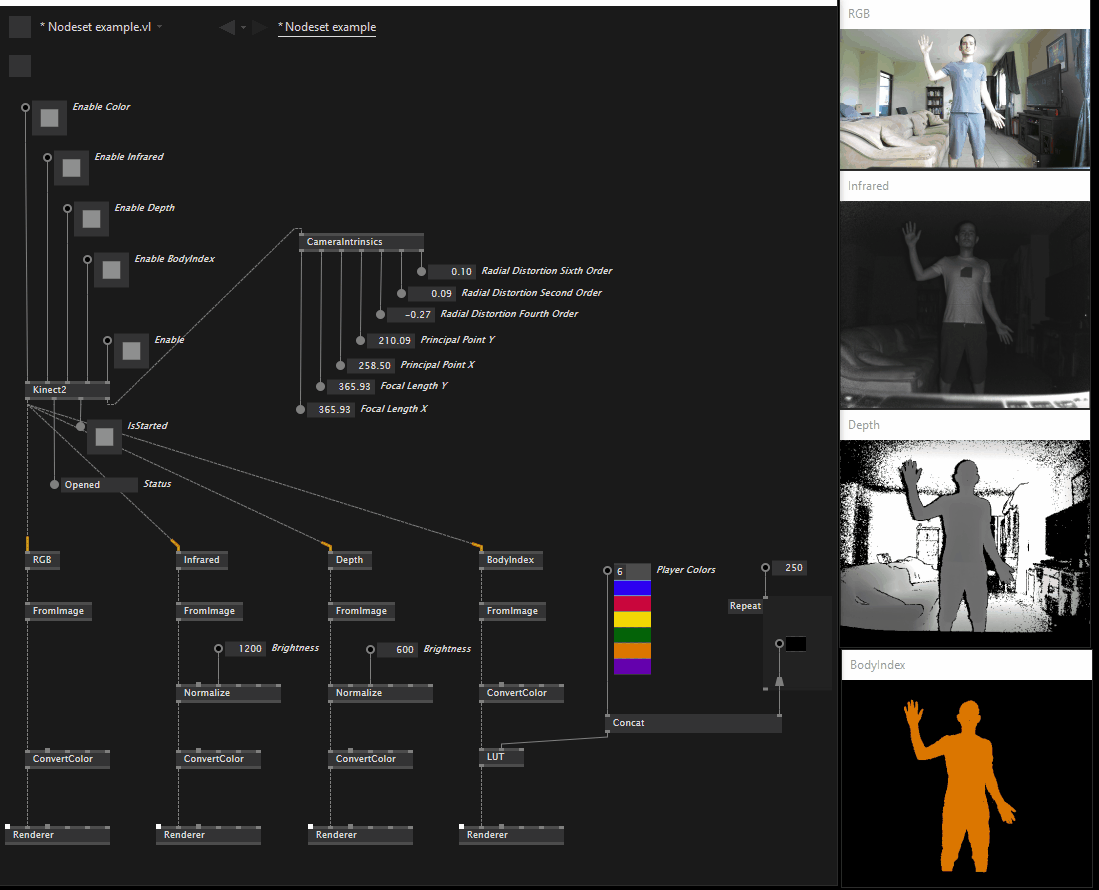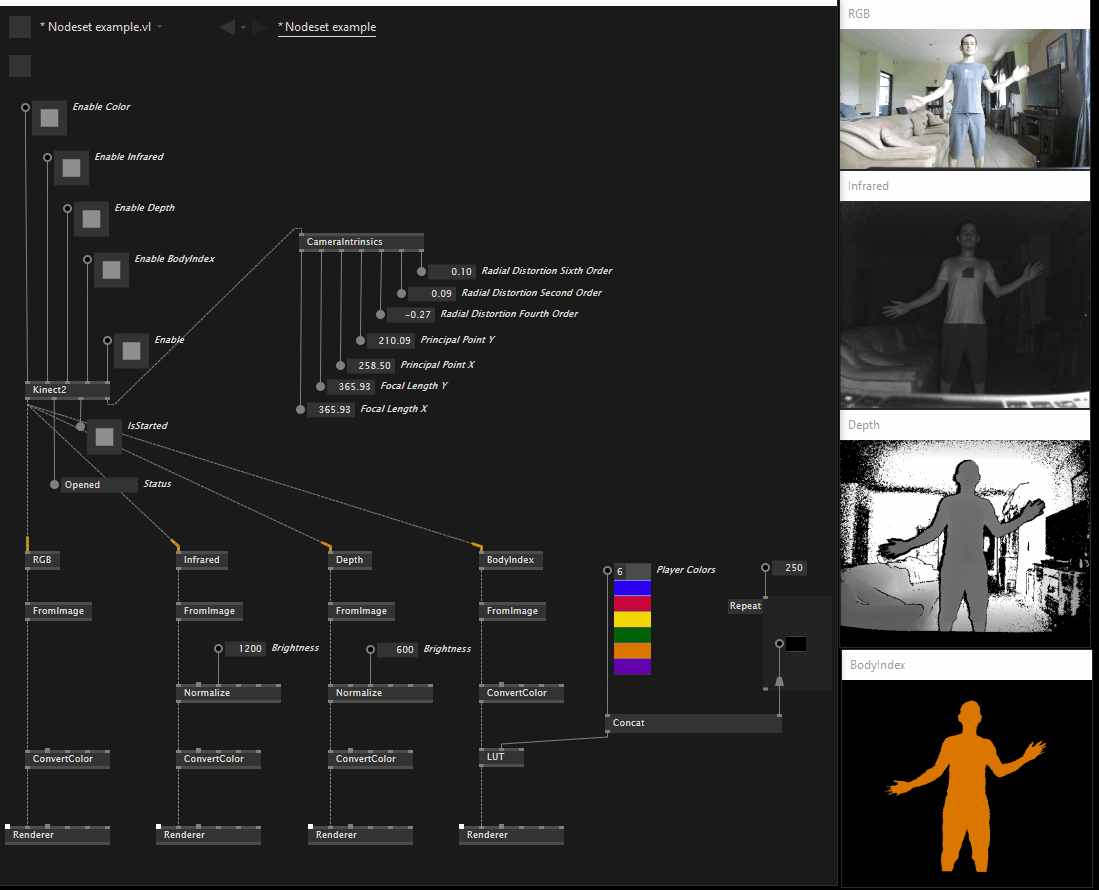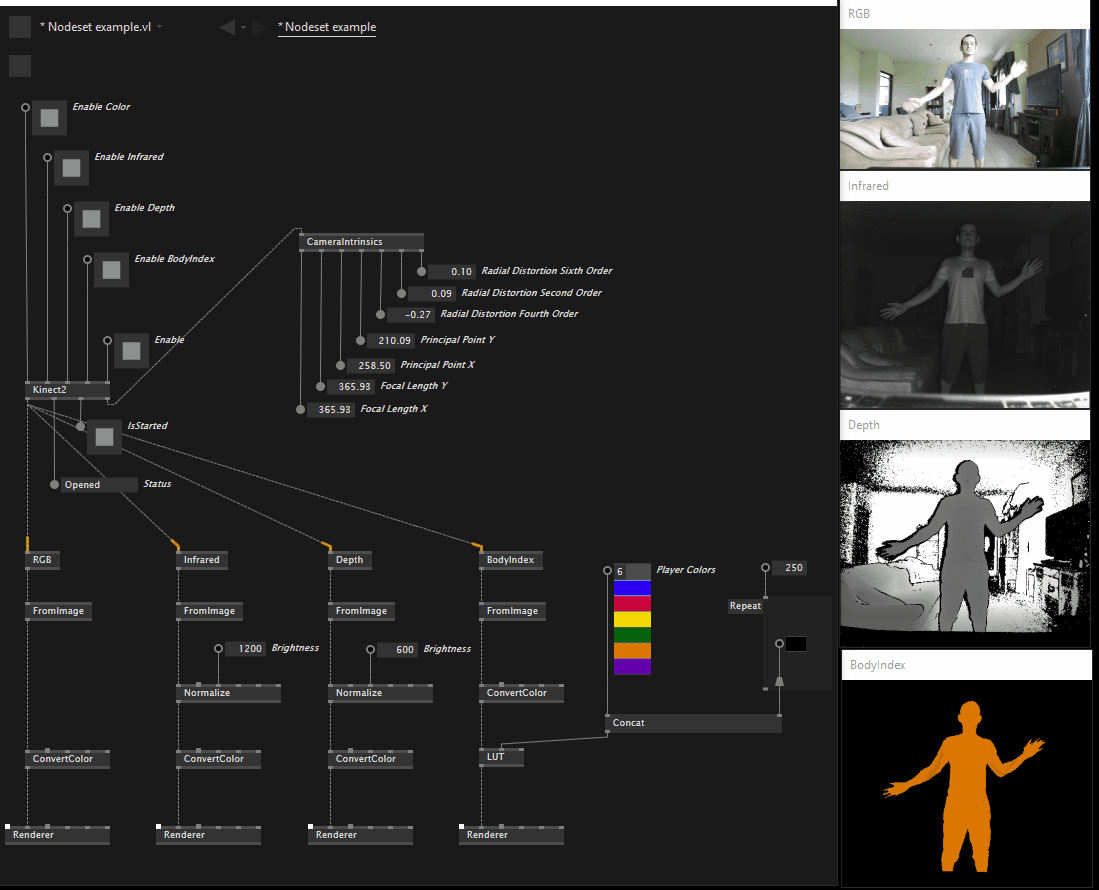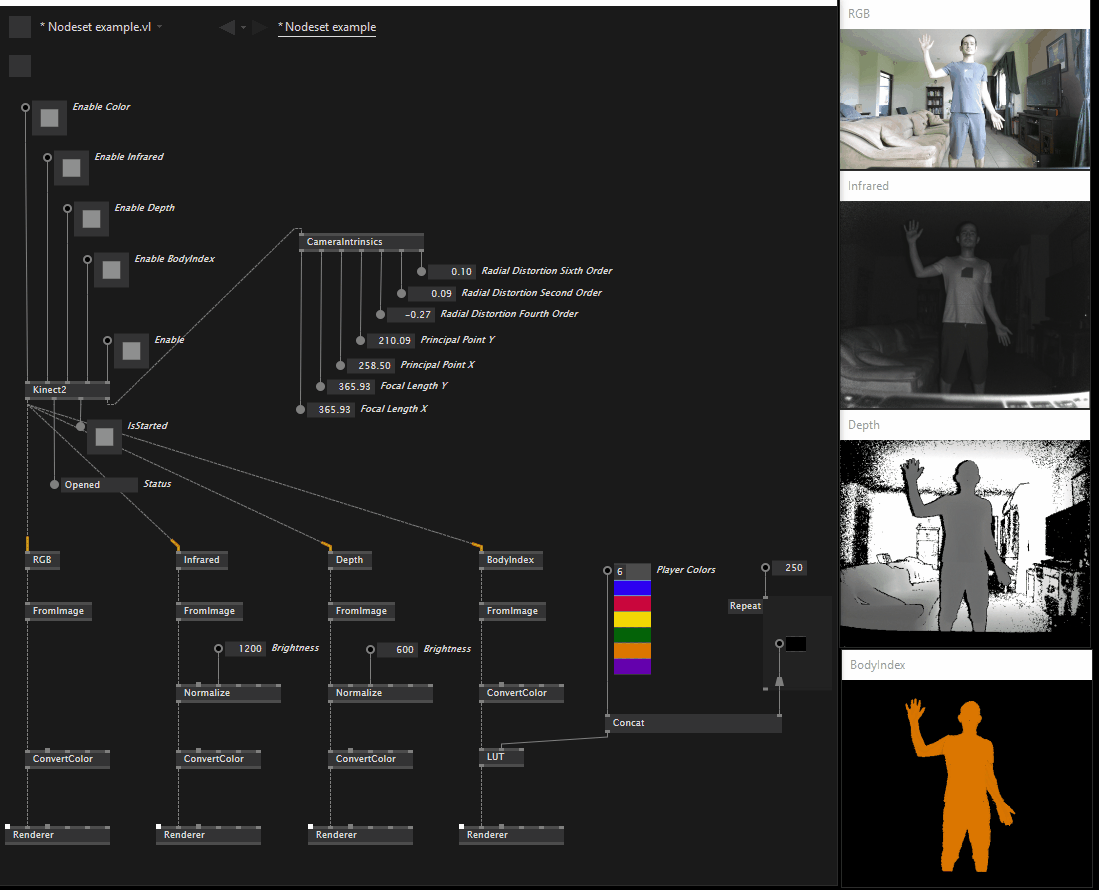
This is an example of how the teaser a few messages above would look in the new version:
So far in our tests everything seems to be behaving as expected with this new approach and you can try it yourself by checking out the observable-based branch on the project’s github repository.
It would be very valuable to hear any opinions regarding this change before we fully commit to it so please join the discussion and share your thougts.
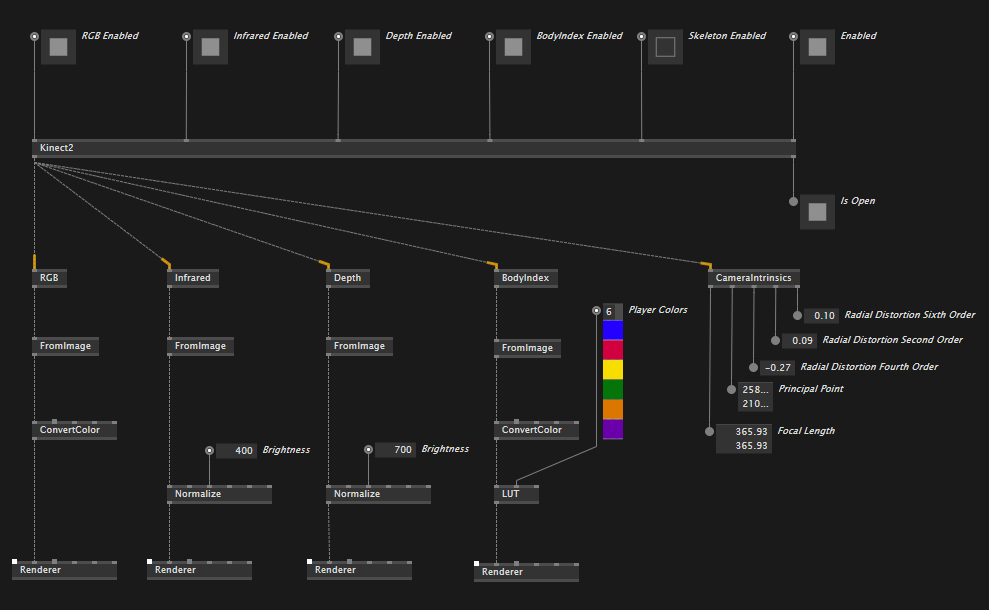
After some discussion on the model proposed in my previous post the decision was to stick with our original plan, so per-stream specific nodes have returned and are now available in both standard and reactive versions, the same is true for skeleton.
This is what the Overview help patch looks like as of version 0.1.13-alpha:
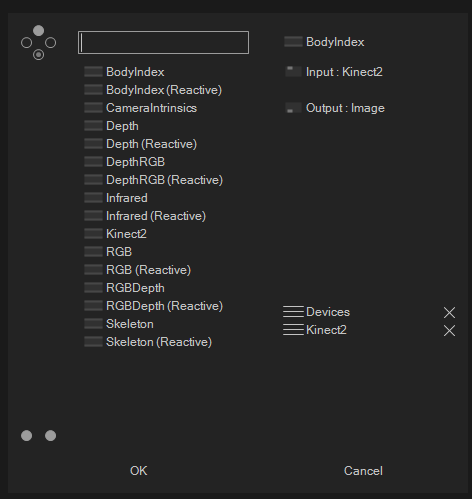
Go ahead and give it a spin, you can intall via nuget following the instructions here.
We have added help files with an overview, a Skeleton usage example, and a Skia Depth PointCloud example as well. Make sure to check the examples out at:
this is awesome (and a great learning ressource)!
there’s one thing i miss though - the quaternion output for the “head” joint, which is always zero. the dx11 kinect-nodes have the same output, but the quaternion for the head can be retrieved via the “Face” node.
did you consider porting the face functionality as well? head orientation would be nice to have to know in which direction persons are looking.
I did not know that head quaternion is always 0, I wonder why that is, will add it to my list.
In any case Face functionality will be implemented in the near future but I have other things at the top of my list at the moment. I will try to get this done sooner now that I know someone needs it :)
In any case thanks a lot for reporting and stay tuned.
This is all CPU so your machine might have something to do with it, but do play with the scale factor to improve perf at the cost of detail, also avoid any IOBoxes showing data as this will put the patch in Debug mode (which is why closing the tab helps).
Lastly, I am currently working on a PointCloud specific node which promises to be easier to use and hopefully more performant.
It is scaled by .42 as it is in the patch, its the repeat region that is sapping the cpu 100,000 clicks. I guess the issue is looping through all those points.
@catweasel I just updated a draft version of the new PointCloud node and help patch. Scaling and Mapping features are still WIP but performance should be better compared to previous solution. Please test version 0.1.16-alpha and report.
hi, is it possible to have the “grabbing” gesture available as well?
i tried to use the distance between the handtip and the tumb node, but it does not seem to have the same reliability than their grabbing from the SDK.
I am not sure if you are talking about the Gesture recognition section of the API or about the Hand tracking section of the API but short answer: No these are not yet implemented, they will come in a near future.
Of course you and anyone else is more than welcome to collaborate to the repository/libray in the meantime to get it done faster.
i am talking about the hand state, which is not really a gesture, so i guess it is part of the Hand tracking API.
in VVVV and i think in their SDK there are 5 states that can be distinguished for each hand:
open
closed
lasso (index finger only)
unkown
not tracked
although the data is super bad, it would still be nice to have it in VL as well…
I will check your code and their c# code where it is used, no gurantees though :>
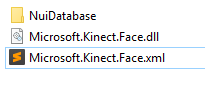
so that it sits right next to Microsoft.Kinect.Face.dll like so:
This will probably be reworked in the future so that the copying is automated.
Everything should work out of the box after that. If you see the RGB image but no face detection, try to move so that your full upper body fits in the frame (at least for initial detection).
Teaser:
Also, Version 0.1.32-alpha adds support for basic Hand state recognition.
Summary
Recognized states are Opened, Closed, Lasso, Not Tracked and Unknown.
Tracking certainty information is also provided.
New help patch showcasing the feature can be found at:
VL.Devices.Kinect2\help\Kinect2\General\HowTo Work with Hand data.vl
Huge thanks to Elias for all the patience and help!
Update regarding Face nodes: the newest versions of the nuget now ship with NuiDatabase directory meaning you no longer need to do any extra steps for Face recognition to work.
A simple nuget install VL.Devices.Kinect2 -prerelease should leave you with a working environment out of the box.
If you tested Face functionality with previous versions it is recommended to clean up your vvvv’s packages removing any Kinect Face directories and or NuiDatabase directories.