I’m trying to implement the counting sort algorithm for points in 3D with compute shaders.
Like other sorting algorithms it works by dividing space into cells, lets say 3x3x3. It then counts how many points are in each of the 27 cells (aka a histogram) and generates what is called a prefix sum, which for each cell stores the sum of all points in all cells before it. In other words, when using this to sort, it tells me the start index of where in my output buffer the points of this specific cell should go.
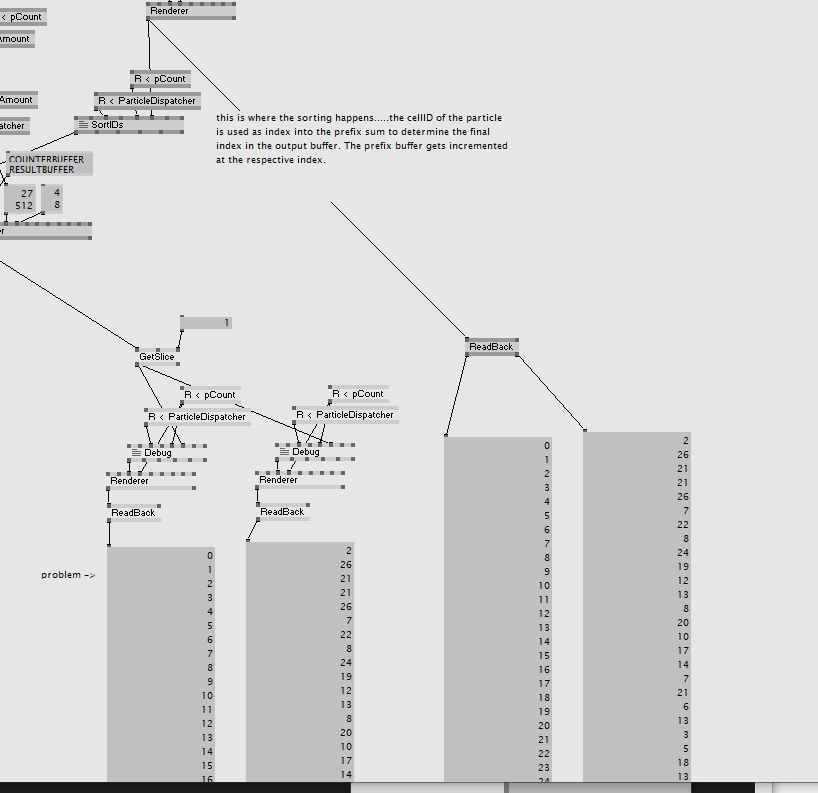
As a last step the algorithm cycles through all points and uses the point’s cell-ID to look up in the prefix sum buffer at which index to place the point in the output buffer. Finally, when a point from cell x gets assigned to the output buffer, the prefix sum value of cell x gets incremented by 1.
As a result the points are sorted into cells as intended.
I’m struggling with the final step/renderpass, which should be simple:
I got 2 shaders here, the first one simply copies my prefix sum buffer to a RWStructuredBuffer so I can write to it (in the other shader)…not sure if this is how you do that in general if you need a writeable buffer coming from another renderer, but seems to work:
StructuredBuffer<uint> Counter;
RWStructuredBuffer<uint> OutputBuffer : COUNTERBUFFER;
[numthreads(1,1,1)]
void CS(uint3 tid : SV_DispatchThreadID)
{
if (tid.x >= elementCount)
return;
OutputBuffer[tid.x] = Counter[tid.x];
}
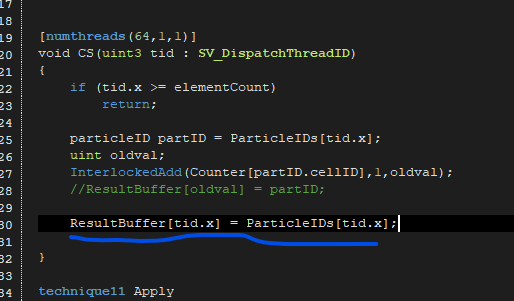
The second shader does the work. The struct ‘particleID’ stores point-ID and cell-ID for each point/particle:
StructuredBuffer<particleID> ParticleIDs;
RWStructuredBuffer<uint> Counter : COUNTERBUFFER; //prefix sum
RWStructuredBuffer<particleID> ResultBuffer : RESULTBUFFER;
[numthreads(64,1,1)]
void CS(uint3 tid : SV_DispatchThreadID)
{
if (tid.x >= elementCount)
return;
particleID partID = ParticleIDs[tid.x];
uint oldval;
InterlockedAdd(Counter[partID.cellID],1,oldval);
ResultBuffer[oldval] = partID;
}
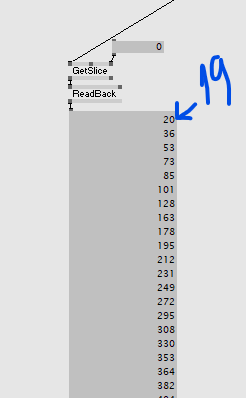
Unfortunately this doesn’t work. While the cell-IDs in the output buffer seem to be ok, the point-IDs flicker. There seems to be an issue with the InterlockedAdd(), but I don’t really have experience with atomic functions. Maybe the issue also is the copy in the first shader and when all of this is actually executed…
Any help/hint is much appreciated!
Example patch below
gpuSort.zip (7.3 KB)
thank you!