
What would you say to be able to navigate in your large pointcloud realize using PoTree Converter in your favorite application? I dream of it but I am not good enough to be able to do it alone.
So if you want to help me, do not hesitate.
www.potree.org
Its something I’ve considered but not got round to ;)
That is my first test to import.
https://www.dropbox.com/s/5q2f7x7934cqfv0/potree-master.zip?dl=0 (5.906 ko)
Great activity, it would support it. Need to display large pointclouds in realtime (which is now 90fps) is expressed here in the community quite often. PoTree does solve lot of issues related to that. I’ve been able to render about 40 milion points realtime, which is more VR screen pixels count.
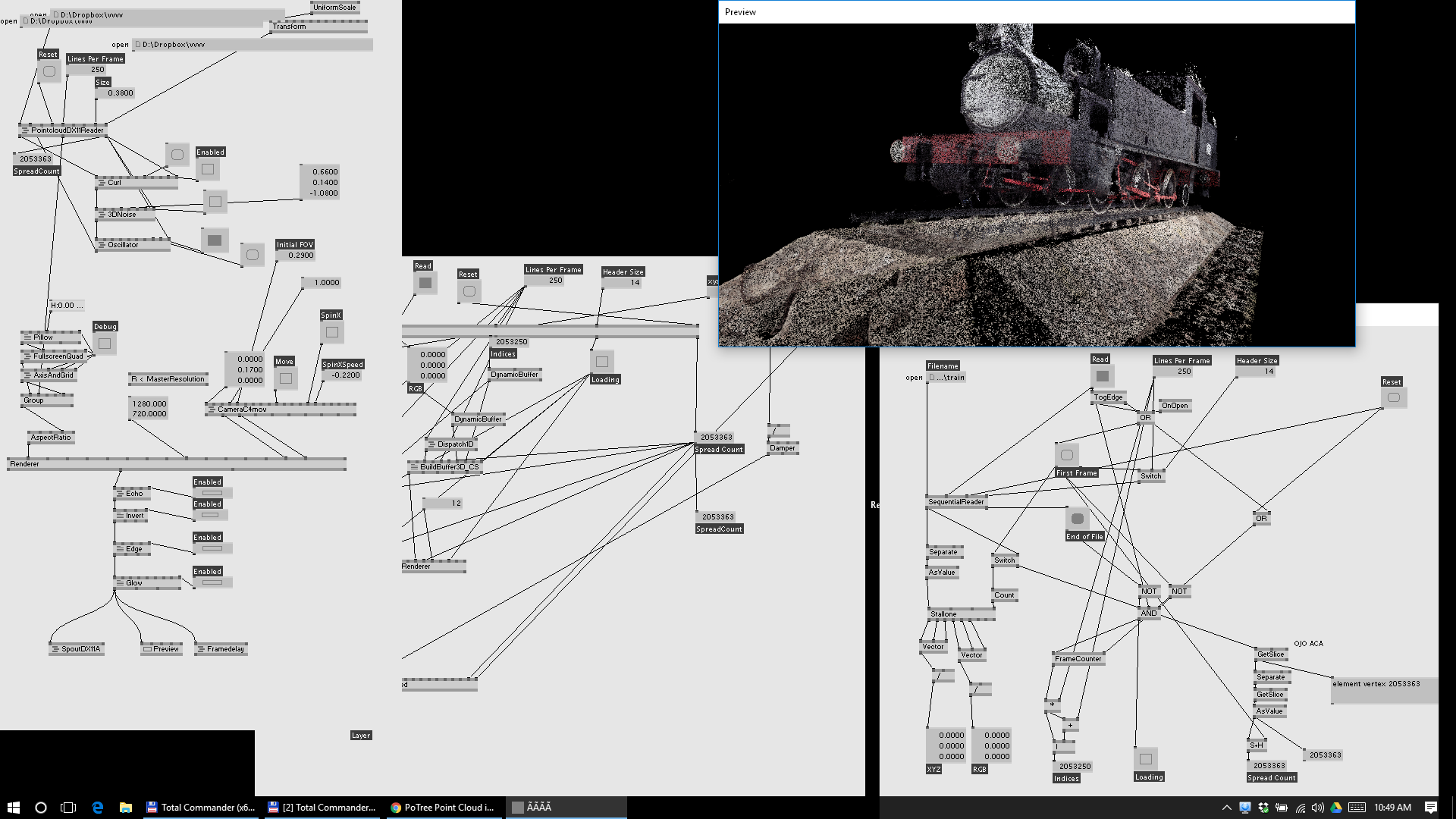
I’ve been playing with photogrammetry and pointclouds during the past few years. Some of the datasets we made do have more than one billion points.
Asynchronously reading the PoTree files into GPU memory should be fairly simple, I do have the prototype. Choosing the right segments needs more effort.
Ok, thank for informations. I will try to play with dx11… It should improve performance.
Several users are talking about that on the node proposal area
Im working with Pix4d for along time also, pointclouds can get big, really big!
DX11 and buffers is the way to go. Kyle and Colorsound helped me with a buffered sequencial reader for huge PLY files ( <2M rgbxyz pioints ). I will check with them to clean it up … this potree reader is amazing! good job
@andreasc4 I tend to convert ply to dds files with xyz in the rgb and rgb in a 2nd dds file, then you can use a null indexer to draw the points, you can get up 6m odd that way, but I want oct trees so you can cull early from the frustum and work with stupidly big ones!
don’t think there is any better way then just a frustum test directly on gpu, i guess the best way is still to write just a binary file… this new dx11 update brings also this immutable buffers witch gonna make whole thing faster…
The point is to cull on broader bounding boxes rather than per point, whether thats cpu or gpu is not important, its to do it before you get to processing every point.
@andresc4 @everyoneishappy @colorsound
please can you give us some more infos on this:
a buffered sequencial reader !! how do you sort/index the data to read?
;)
@antokhio regarding the performances do you think reading a huge binary file on the cpu
which contains millions of data should work?
in your scenario we first load all the datas and do the frustum test afterward
but in the case of a giant file // finite vs infinite world ;) not sur vvvv an handle this?
@circuitb well obviously in the case of “infinity” you would want this LOD’s and streaming stuff, it’s actually possible already with filetexpool, pooled resource it’s what you actually whant… But if it’s a single object 6m points should do it with immutable already no problem…
and i want to load everything in GPU memory and then only render whatever is necessary…
As I’ve said above, I’ve done 6m already, but we were always wanting more! As much so that when you look around, there is a background detail, I imagine it being cubes of dds encoded points, non blocking filetexture loading, and just loading the cubes in the frustrum, then LODing the points you can see. Oct trees like this already do the sorting into cubes, so it should be possible to do something like this, just need to find the time!
@circuitb this was our first approach
reading the points from a PLY , not binay, parsing a few lines to get the correct vertex count
and finding the rgbxyz vales, once we have that list, Kyle and Colorsound did the magic the sequential reader reads by blocks, and send that data ( and the index of the block ) to 3 different buffers, index, rgb xyz
We were able to get up to 3m, it super cool to mess up with instance noodles and the position buffer,
I just have experience on making the pointclouds, this was 95% Kyle and Colorsound
This topic was automatically closed 365 days after the last reply. New replies are no longer allowed.