im having trouble displaying alot of Data. Its 4 CSV Files with 40.000 Rows and 6 Colums.
Format is:
Date | Time | Value 1 | Value2 etc
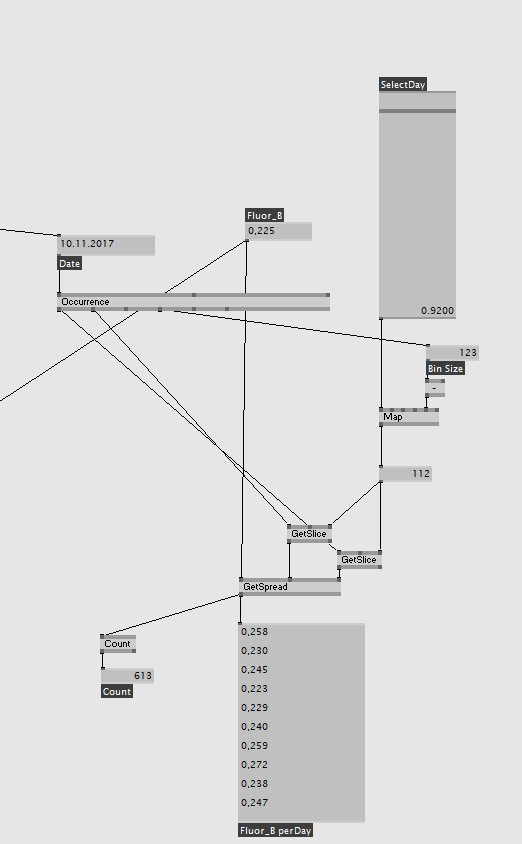
Currently im spliting the Data with Occurance by Date and allow the user to select a Day of the data.
It works but this is ofcourse not working with exeptable performance.
i need the Data from the Huge Files to be grouped by Date.
Currently i have 2 Possible solutions.
Render out All Graphs per Day as dds files ( not best solution no Data Mapping possible / no animations )
Split the Huge CSV into many CSV Files, One for each Day in the Data.
This would result in a Folder per File with ~400 small CSV Files with about 100-600 rows.
With these i would just select the File string and load only one of them for the Day selected.
So my questions are: is the a better solution im not seing? All Database / Format options ive found would also result in Heavy String Operations.
Does anyone know a tool or Script to separate the CSV File into many files grouped by Date?
I Could do this in VVVV…
Would the Solution spliting it into many small CSV Files make sense or would reading them result in bad Performance?
Just asking to make sure im not wasting time to find out my solutions make no sense…
just a general hint:
usually string parsing and data handling is done once for all data on startup. then you keep computation friendly data (values, colors, pixels) in memory (huge spreads that don’t change or textures) and read from that when you need it.
this might result in long startup time, but then fast data reading. also with VL you could do such things in the background without blocking on startup.
Thx for the reply, it helped and im very oddly initializing on startup - switching through the scenes then stop evaluating these nodes after startup and everything is working at 120fps
Heres another clue if anyone ever has issues with huge csv files:
First try to reduce the dataset to a precision level that is sufficient for displaying the Data.
Basically ive rounded values in Excel, which reduced the filesize and loading time a lot. Its an annoying step since it would need to be done for every new set later integrated but it was worth the time. Sadly it is a potential source for errors.
I know this is not always a possible solution and often wont help performance, but in my case it helped.
As soon as im more comfortable with VL i will try updating this project for learning purpose.
If someone has Examples in VVVV and VL for huge data parsing and handling feel free to post links etc