hi all,
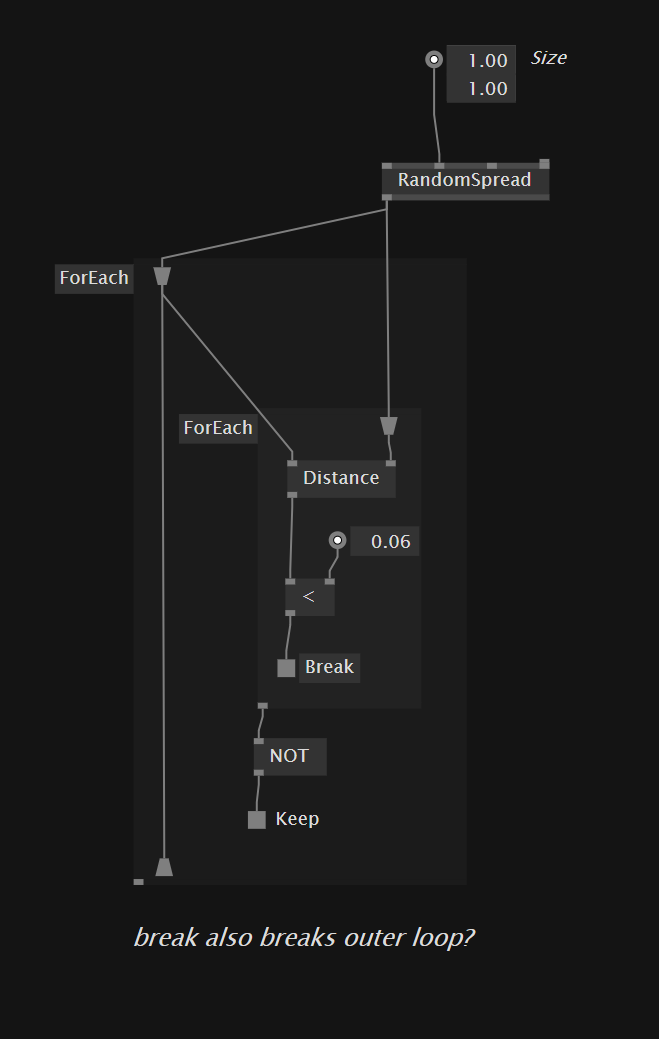
how do I filter a 2d random spread for elements that are too close to each other? Tried multiple times but failed gloriously. I also don’t understand why the approach in my screenshot does not work. Please can sb explain this to me?
thx

hi all,
how do I filter a 2d random spread for elements that are too close to each other? Tried multiple times but failed gloriously. I also don’t understand why the approach in my screenshot does not work. Please can sb explain this to me?
thx
Why do you need a break? if you are looking for neighboring elements I dont see what break does in your case. “Keep” must be sufficient. Think of it like this, you have a collection of elements [n1, n2, n3] and you want for each one of them to create a jagged array with its neighbors [ [n1,n2], [n1,n2,n3], [n2,n3] ] then you want probably to exclude the same term (the “self” - with the same index) so you should keep [[n2], [n1,n3], [n2]] which is fairly easy by comparing indices in this case. I hope that I got well your problem, you may check the attached patch.
find_neighbors_by_distance.vl (21.8 KB)
*to filter out distances shorter than “x” just change the logic operator from “<” to “>”
Your inner loop keeps all objects that meet the condition - but for every outer loop! So you end up with a lot of duplicate objects. The color debug was a little confusing.
find_neighbors_by_distance_edit.vl (20.1 KB)
I try to not keep the frame of the outer loop, if any frame of the inner loop meets the condition. So in my understanding, as soon as the inner region breaks and bangs, the outer region is not kept. And since there are no more iterations on the inner loop, the outer one processes the next item.
This reminds me of the Packing Circles & Packing Characters example patches.
It’s not exactly what you are looking for, but I do think, that the algorithm used in there is quite intuitive: they start with a valid (empty) spread and only add new items if valid. That way you never need to filter out anything that is invalid.
However, if you ran into a situation, where the spread is already “messed up”, and you can’t prevent that and you have to filter that already messed up spread, still, I would try to start clean within the filtering algorithm: again start with an empty spread and only copy those elements over that will not mess up the newly created spread.
I find it easier to reason about the problem when having a bad and good spread… Rather than messing around with indices…
filter spread.vl (27.7 KB)
perfect! would you care to explain why the example from my initial post is not working?
When iterating over the same sequence twice in a nested fashion you will end up “seeing” all permutations:
Let’s say your sequence contains three elements a, b and c.
Then you will be confronted with those pairs inside the inner loop:
(a, a), (a, b), (a, c),
(b, a), (b, b), (b, c),
(c, a), (c, b), (c, c)
The problem is that you compare a with a: the distance is 0. So you need to take care to not compare any item with itself.
But also, imagine a, b, and c are arranged in a linear spreaded way:
a__b__c
Let’s say this distance is too small. Wouldn’t you want to keep a and c then and just filter out b?
a_____c
By filtering out b the outgoing spread would be valid.
But when you always compare all items to all other items you will filter out everything. So even if you take care of not comparing a with a, b with b, and c with c, you still filter out all the items, since a is too close to b, b is too close to a, and c is too close to b.
That’s why I would say it is much easier to start with a valid spread and keep it clean.
This topic was automatically closed 365 days after the last reply. New replies are no longer allowed.