
Hi.
This is one for the DX11 & Shader Experts.
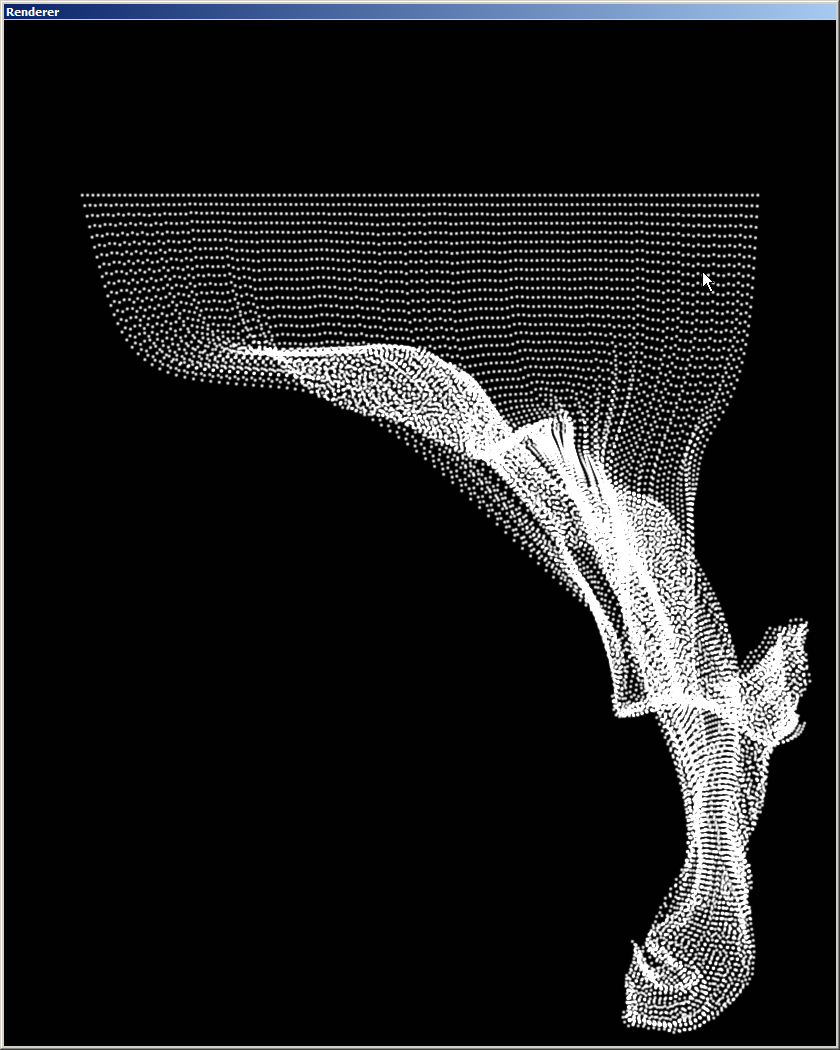
I’ve been trying to implement a cloth simulation with a physics spring system based on verlet integration. And I pretty much succeeded, as you can see in the screenshot, BUT I still have a very basic problem:
Since everything happens in a compute shader, the whole calculation is based on how many thread groups are initialized and how many dispatches are done. This seems to greatly affect the simulation and if I use a “wrong” thread configuration, feedback loops appear up to the point that everything explodes (kind of). My guess is, that the number of threads and threadgroups has to correspond with the shader kernels of my graphics card or something, because I found a stable configuration, that runs like a charm on my machine, but totally gets out of control on a different one. For some reason it works with 4 dispatches and 4 threadgroups for 4096 points. This configuration is also scalable, because it works with 8 dispatches, 8 threadgroups and 16384 points as well (And so on). So there seems to be some direct connection, but I can’t figure out a general rule.
So I guess my question would be:
Is there a right an generally working combination of threads and threadgroups for this application, or do I need do synchronize the threadgroups? Or maybe I made a completely different mistake and all this has nothing to do with threads?
If something in the code or the patch is not clear, please ask.
All thoughts and suggestions welcome!
Thank you all very much for reading all this! ;)
Cheers
Verlet Patch - final.rar (1.1 MB)