Here is what I am trying to do and wondering if this has been solved before:
I have a DX11 render setup with a camera and a lot of objects. I want to check if the objects are visible through the camera at a given time. If they are not visible I want to increase the camera distance till they are visible. The distance the camera has to move back is calculated rather than an iterative process where is checks and simply moves back a certain amount and checks again.
I understand what needs to happen conceptually and even mathematically. Here is the rough outline:
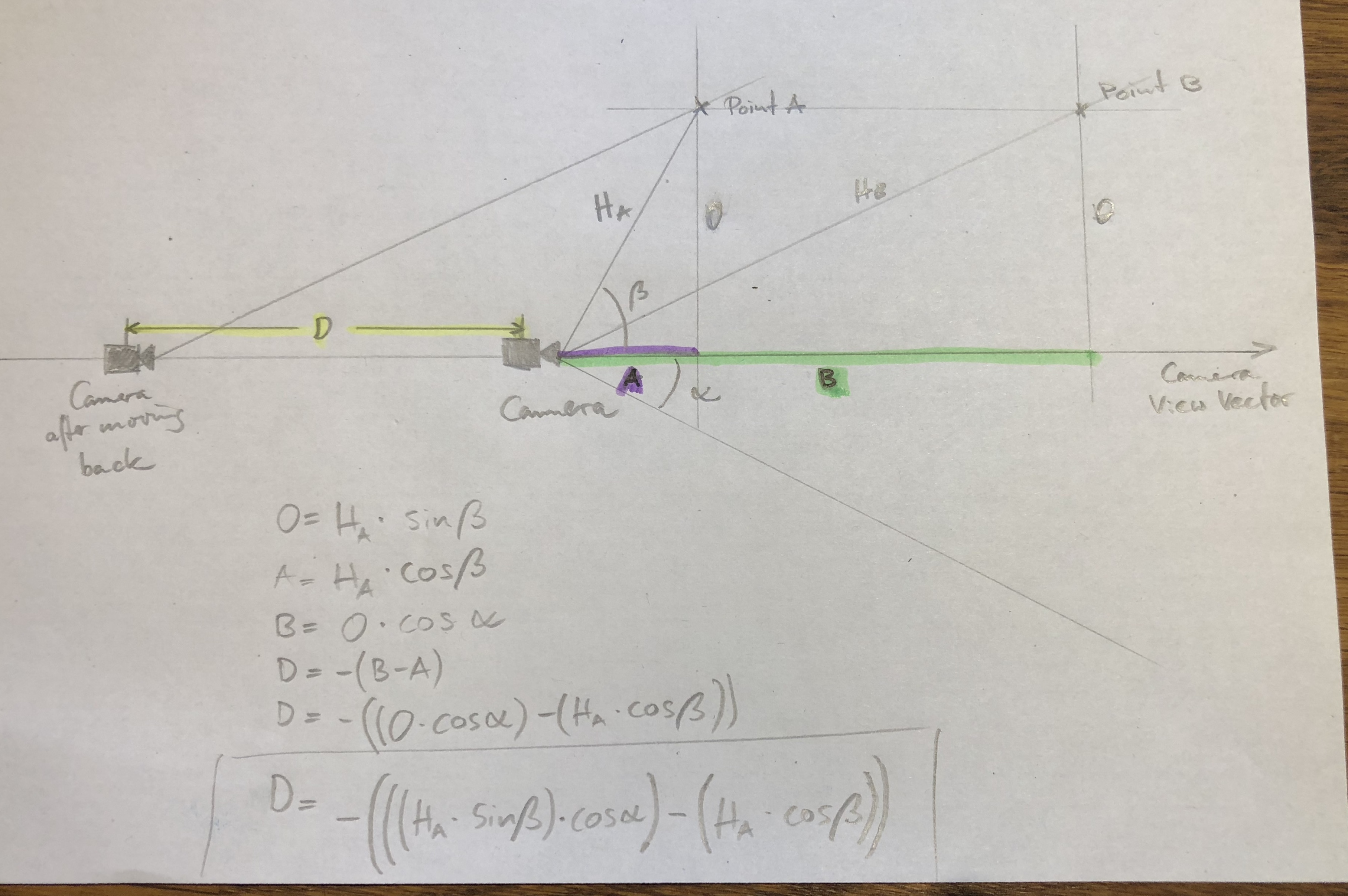
get the vector of the camera, basically the vector between the Position of the Camera and the interest of the camera
Using the FOV of the camera gives the angle of opening. For simplicity lets assume that the total field of view of the camera is basically a cone, which should make these calculations a lot easier, since then we only need to consider angles in one plane and it becomes simply a 2D problem
get the vector of the objects relative to the camera, so again basically a line between the camera position and the object position and get from that the distance and angle (Ha and b).
Using the height (O) and FOV angle (a) we can calculate the distance it would take the camera to be at to get the same height as the 3D object.
You can reduce it to one formula where you just need the distance between camera and any object, angle between view vector and line to the object and the FOV.
If you have multiple objects you simply sort the angles and only calculate D for the largest one. If all objects are already in view it will move forward to zoom in as close as possible so the outermost object is just visible, since D will then become positive.
I could probably build it in Grasshopper, but in vvvv I am not so sure.
Maybe there is a simpler way. Maybe its already solved. The idea is to get something similar to “Frame All” in Maya and other 3D software, but it should only affect the distance of the camera and not the rotation of it.
@sunep thanks. Its not quite what I am looking for, but still worth including so it doesn’t render objects that aren’t even visible. But since it seems like its super quick (4 ticks when running in the FrustrumTest help file), it might be good enough to combine the 2. So normally it will just invalidate any geometry not visible (they are all instances anyways) and if I want to frame all I just move the camera back till none are invalidated. That would be a quick and dirty solution…
I gave it a quick try using the FrustrumTest help file and using a frame delay to move the camera back till the number of failed objects is 0.
Pro: it works, its not expensive in terms of ticks
Cons: its either quite slow or moves in large increments and thats when its still running at 120fps. In our main patch, whihc runs at 30fps if you’re lucky it will be too slow
How about computing the bounding box that contains all your objects and make your camera moves to depends on it ? This way you would not have to FrustrumTest one by one and wait for the camera to reach the last.
I am partly doing that already with the position of the camera. The Center of interest, or target of the camera is already in the center of that imaginary bounding box or rather its calculating the average position of all objects I want to focus on. So its just the distance I need to work out.
That DOES look like exactly what I need, but I dont understand what “f” stands for in their equations:
“…and the process can be reversed to calculate the distance required to give a specified frustum height:”
Aha, okay, f doesnt mean anything. I just have to find the adjacent, when knowing the height and camera angle using tan.
So now the question becomes, how do I get the height of the bounding box for a box that is aligned to the camera? And then I would need to do 2 calculations, right, one of the height of the bounding box and one for the width of the bounding box and then just use the larger of the 2 distances!?
indeed: f in that case just stands for “float32” (as otherwise in c# a real number would be interpreted as a float64, ie double, by default)
haven’t tried this, but i’m thinking: convert the 8 points of the bounding-box to viewspace individually. then take minX/maxX and minY/maxY of those. this gives you frustrumWidth and frustrumHeight to insert in the formula…
thanks for your reply. Yes, I think the first step would be to find the bounding box of the objects, but in the camera space, so that to have the bounding box in view with the front 4 points of the bounding box intersecting with the rays of the frustrum (with some adjustment for the aspect ratio of the bounding box to match the aspect ratio of the frustrum. That way you can assure that you just have to translate the camera and always perfectly fit the bounding box.
Is there a way to calculate the bounding box of several objects in a custom space other than world space?
what i thought: compute the bouding-box in worldspace and then only translate the 8 corner-points of that bounding-box to viewspace. from those 8 points frustrumWidth = maxX - minX and frustrumHeight = maxY - minY.
Hm, but isnt the bounding box going to be different, depending on the reference space? The bounding box in view space might have a different shape to one in the world space. Since I only want to translate the camera and not rotate it, the bounding box has to be generated in the same rotation.
One “solution” would be to rotate the objects using the rotation of the camera, then generate the bounding box in world space and then generate the translation vector.
Okay, so I had another go at this and found some good information, which in the end is pretty much what @lecloneur and @readme suggested:
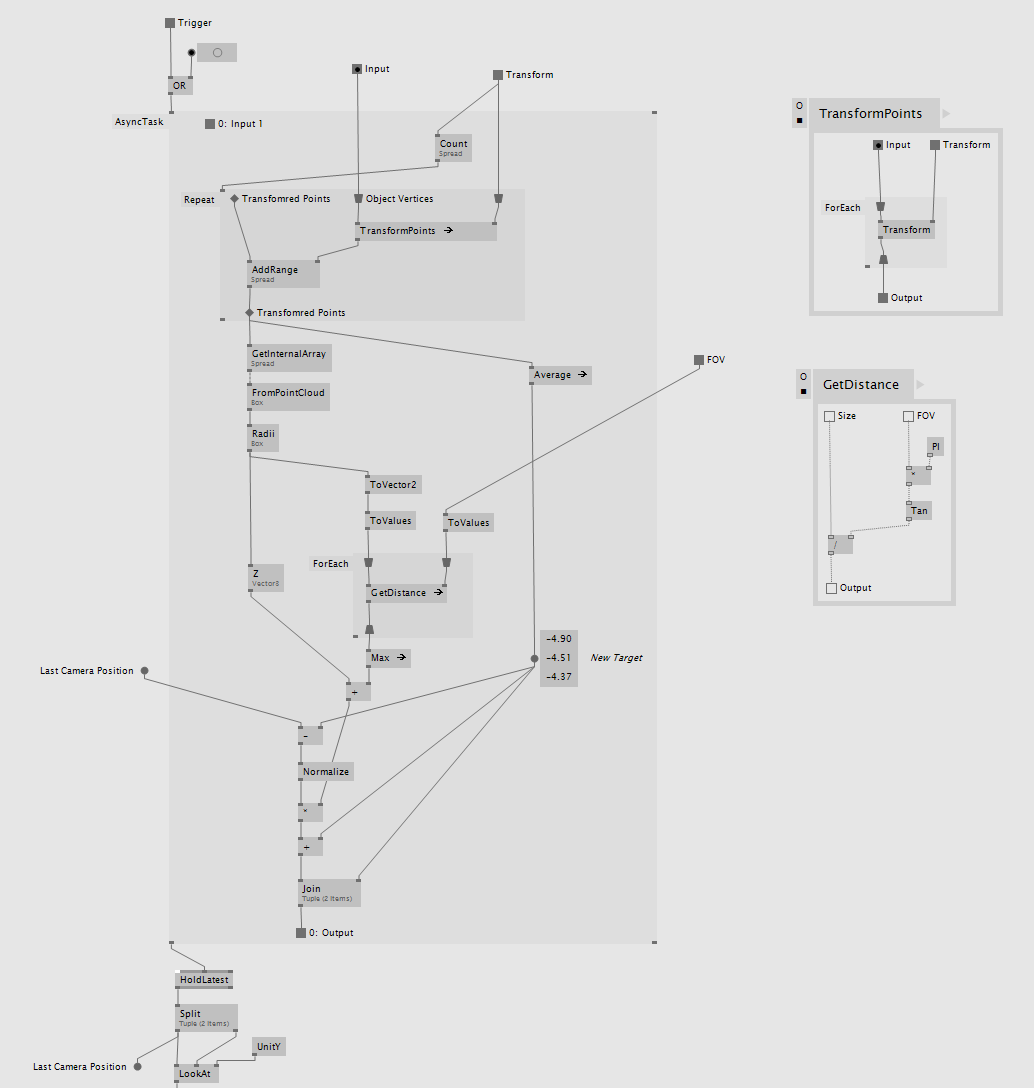
So, create a bounding box around the geometry. Find the largest distance between the bounding box center and one corner - basically creating a bounding sphere. Find the distance of the camera using Tan. Move camera target to center of bounding sphere.
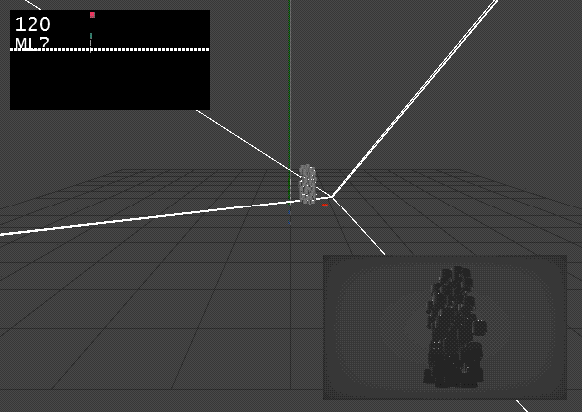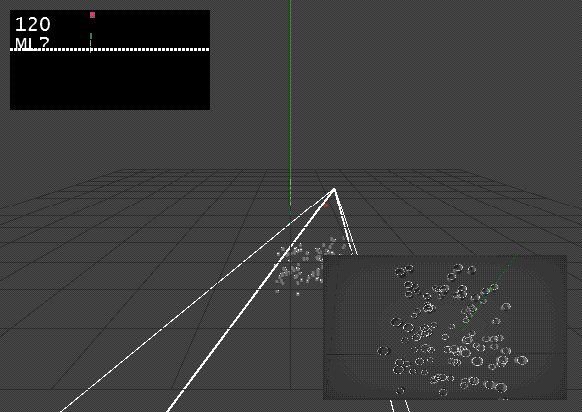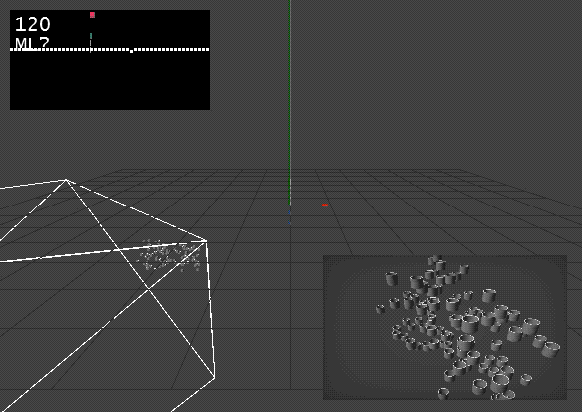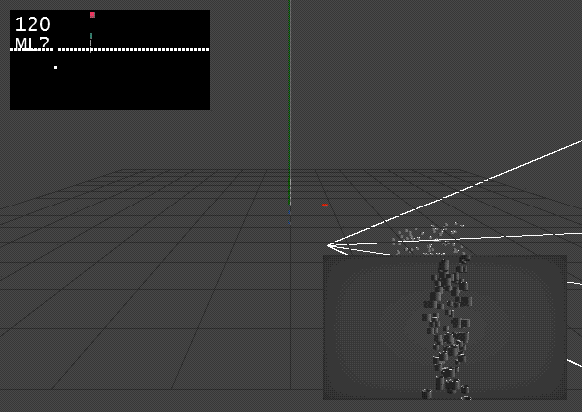
Now that I finally understand what to do, the next question is, how do I correctly get a bounding box around an arbitrary number of transformed geometry? It seems like this should be calculated on the GPU, but I cant find out how to do it properly.
BoundingBox (DX11.Geometry) doesn’t have a help patch and I not sure how to feed it the geometry and position buffer.
Any help much appreciated! I think it would be a very helpful little camera addon to be able to move the camera to fit all objects. Its available in pretty much all 3D software and its used there constantly. Trying to find your way back to your objects using the cameras in vvvv can be a pain in the ass and usually we just end up doing everything around 0,0,0 so that you can easily reset the camera, but camera distance is also a problem, especially when combined with near and far clip plane. The same node could be used to very accurately calculate the optimum near and far clip plane, since this needs to happen for depth information to be optimal (for example for DoF), especially if it has to work at small and large distances.
@antokhio true, always best to work it out yourself. I think I am finally getting somewhere. Proof of concept is working using the bounding sphere. I am sure there is a much more efficient way to calculate the sphere (lots of decomposing transform matrixes, which is always computationally expensive), but hey at least its working. Its not a function that is running all the time, but only for one frame to reset the camera.
I’ll post a working prototype once I have it. I’ll show it in @dottore 's excellent orbit cam.
Update: Meh, Bounding Sphere is not good enough. Its sort of a save bet and will always show all objects, but in too many cases it could zoom in way more.
There has to be a better way not using the bounding sphere and having a proper bounding box in the camera coordinate space.
I saw that as well, i’ll see how we can use it. As a general frustration in vvvv, I find it so hard to do some quick vector, transformation operations and try stuff out. Everything has odd names and some general nodes are just not there. Sure there is always a proper way, using matrixes everywhere etc. But just to try stuff out, its near impossible, even though we totally understand what needs to be calculated.
For stuff like that Grasshopper really is the one to beat. You can do all sorts of vector calculations really easily and more importantly have visual representation straight away. I wish stuff like that was as easy in vvvv and it could be, but I guess thats not really a focus of vvvv. Learning by doing or experimentation is not something you do in vvvv when it comes to geometric or mathematical operations unfortunately.