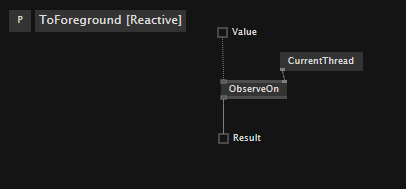
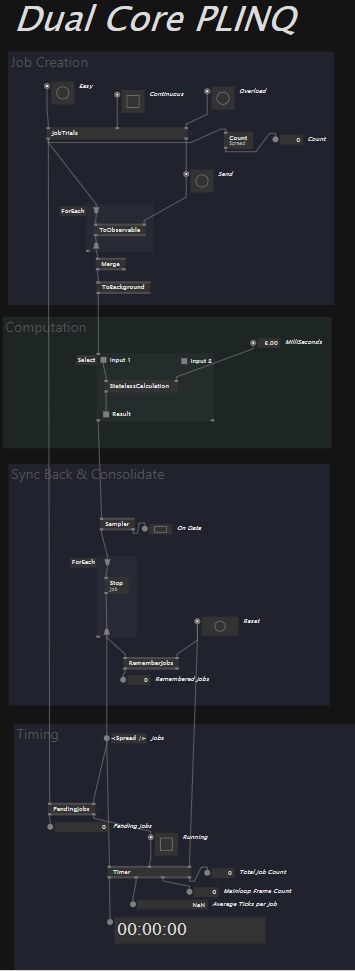
I have been tinkering with async patches lately. There are a few useful regions in vl gamma to that regard, and also a bunch of nodes in the Observable category.
Now I know that observables have been included in vl mainly to deal with async IO and as a way to transcendent event handling, and not really with massive multithreading in mind, so I hope this thread is beneficial to more people.
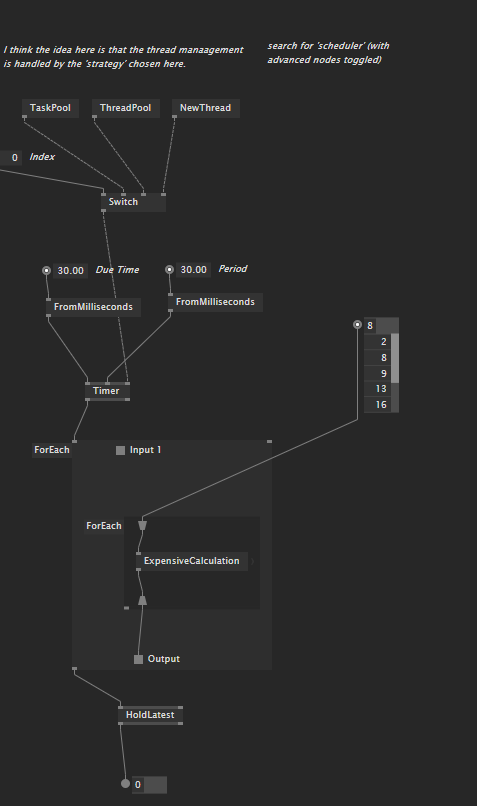
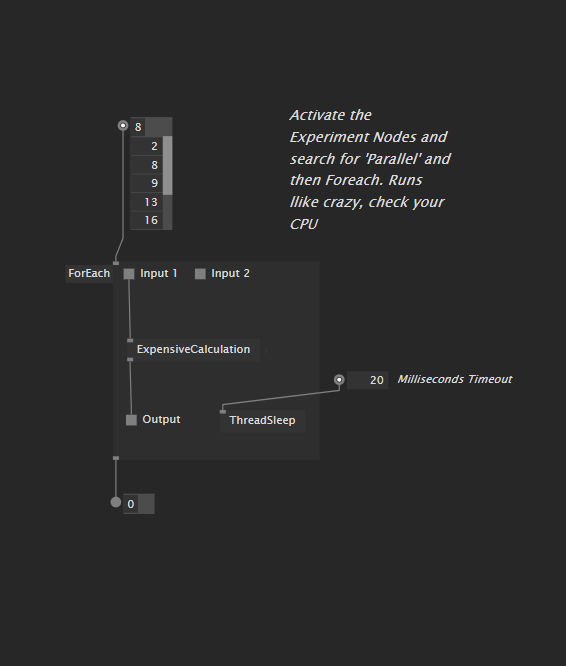
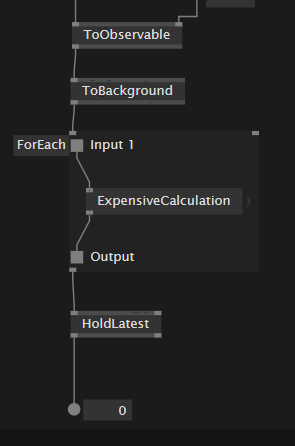
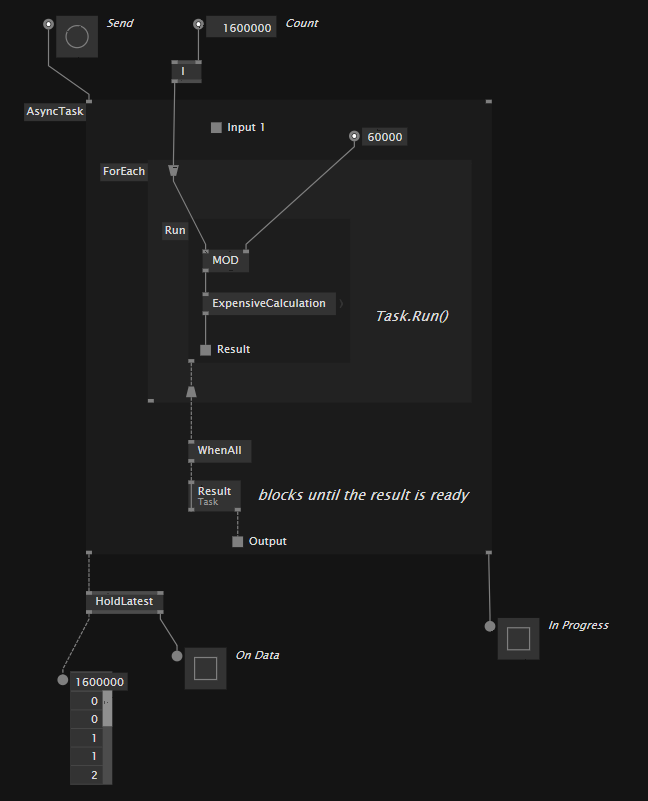
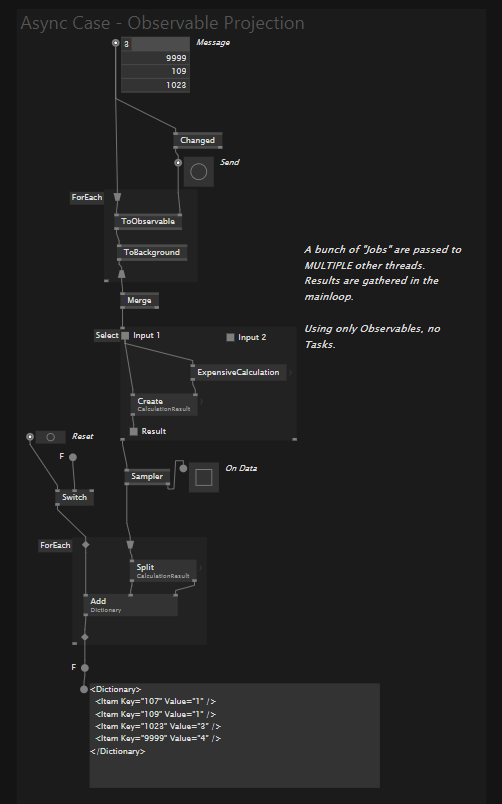
To make sure we are on the same page, please see the attached file with all the experiments: async_studies.vl (115.4 KB)
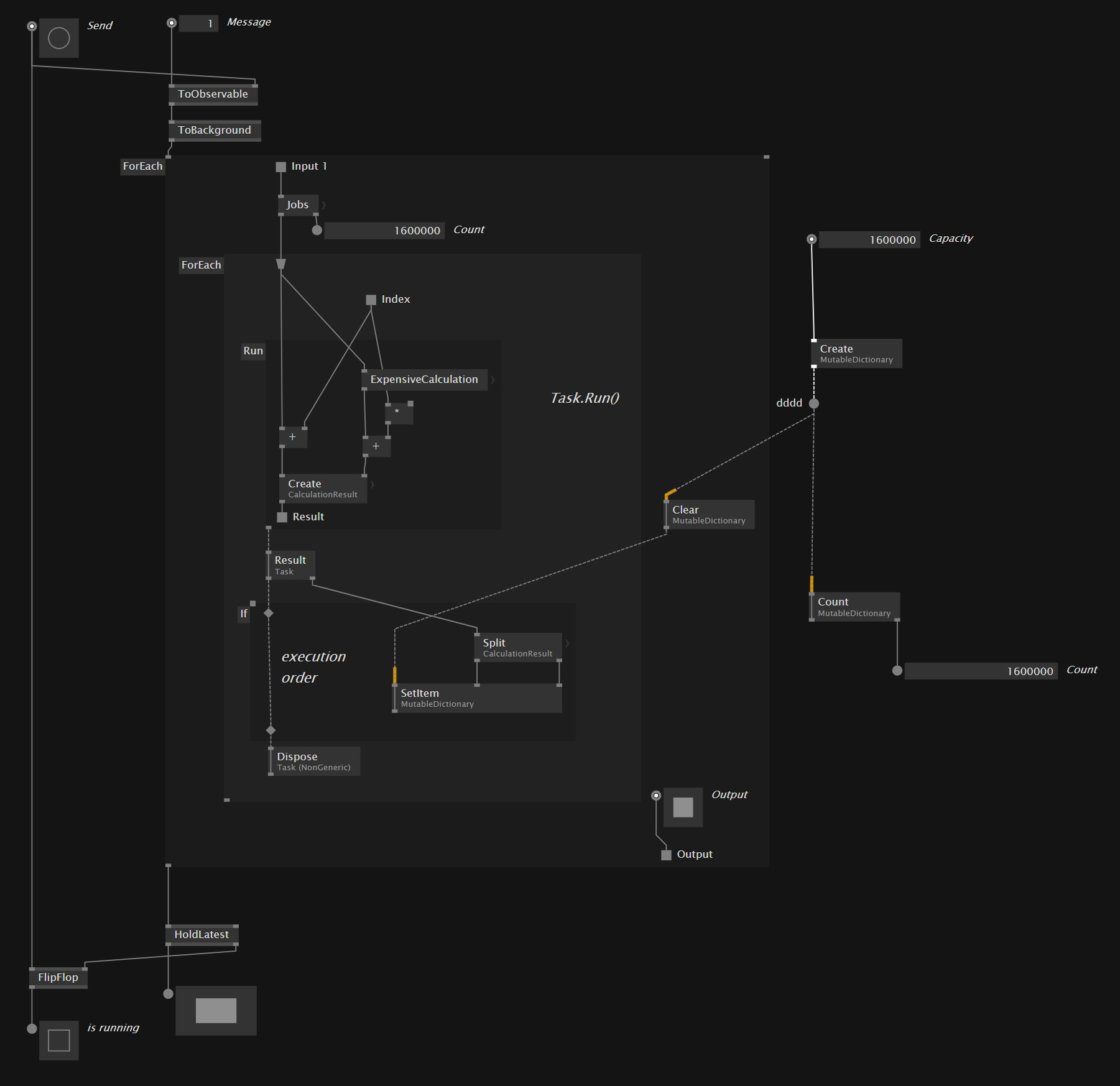
The main goal of my studies I have not been able to accomplish yet: Self-balancing worker threads.
This pattern is quite common. A good example might be path-finding in e.g. Warcraft. Each time one of your night elf unit gets a new order, or detects that its path is blocked, it will ask the pathfinding service to give it a new path. This will be calculated as fast as possible, meanwhile the unit will stand still, but the game and all other units will continue their business. Eventually the service will be done and hand back the result to the night elf unit.
Since there are many units that might want to have a new path, all these requests will be queued in something like a job queue for the service. Also, because we have many many cores, we can split these jobs into multiple workers of said service.
Once one of the workers is finished with its job, it can tell the service that it is done and continue with the very next job.
So technically,
- a bunch of worker threads must be started at the beginning of the app, that have the ability to
- pop the next possible job from the queue (or other way of load balancing),
- run it, and
- send the result back to the mainloop, where it will be inserted into the game model.
Of course this pattern is much more versatile and useful than just for that use case, so in the patch studies it is much less involved, but already shows the necessary boiler plates for simpler async patterns, trying to get to the goal step by step.
I am far from sure that I did everything correctly, especially when using Pads inside regions, so I am more than happy for hints and discussions. And as stated before, I still haven’t accomplished to find a combination of nodes and regions to get as far as is necessary for worker threads.
Can someone help me get further?