This is something i wanted to share for some time now.
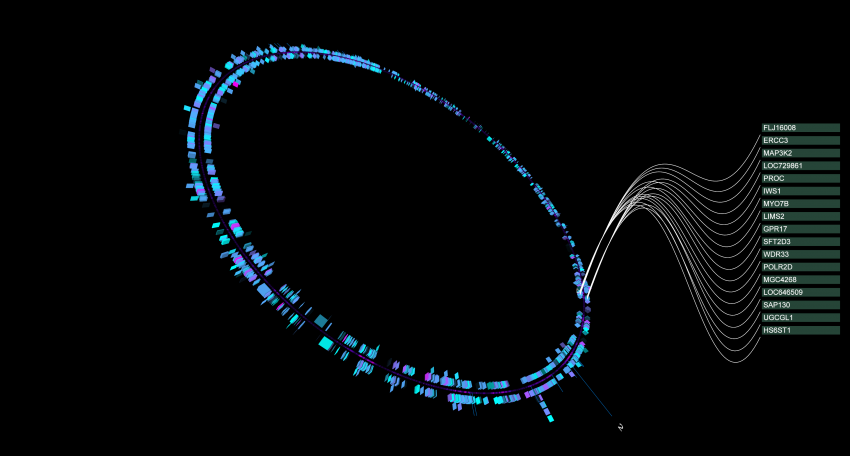
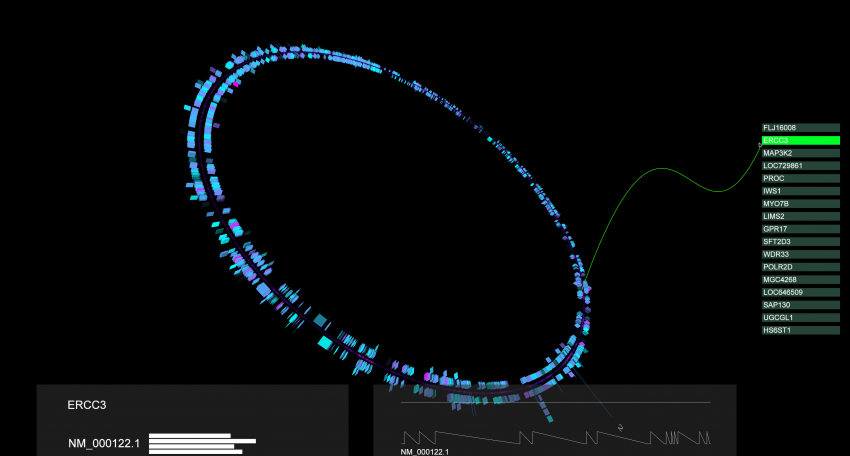
Over the last year i worked on my bachelor thesis in bioinformatics “Interactive 3D Visualization of High-Dimensional Genome Data” in which i basically created a GPU particle system which builds up an interactive chromosome visualization from genebank files, a standard in gene notation.
The data set was a lucky finding due to its innovation and importance for current molecular biologic and genetic research. Although it needed special efforts, vvvv is now the first programming language (as far as i know) with some kind of lib for visualizing the human genome (and of course every other genome) in 3D.
It is still a first step, a proof of concept work and far from being perfect. But further development on the methods could evolve this one to an attractive package for bioinformatics.
The reason why i do not yet create a contribution with it is simply the lack of a good documentation in the modules and a missing line in pin and module naming conventions. I hope to change this as soon as possible.
Thanks to the community who made it possible!
by helping me all the time getting my head around vvvv and providing me with the right input at the right time for almost 2 years now (dottore, kalle, m4d, io, vux, tonfilm, catweasel (thanks for the apple), woei, just to name a few).
Some of your contributions flew into the patch of this thesis as well (properly cited).
So… try it out and tell me what you think.
But be careful, it is a really big patch which takes some minutes at start up and when you load the data.
Thanks,
Dave.
e: slowly began to tear down everything into pieces and making little cotributions out of it.
Thanks! I hope it will be usefull or inspirational for others.
Did anyone run it? I would be courious about your experience with the performance or any problems you encountered. I’m sure that the 10 minutes loading time (vvvv stuck in calculating one frame) could let people think that it crashed…
Does it makes any sense to load one module at a time (that DataFormation ones), to reduce loading times?
If yes, there’s a order (lightest module>heaviest module, please!), or it doesn’t matter?
Cause the patch really gets stuck on my pc!
I found a little workaround that lets me see some more, but when I load RNA module (which, looking down, from left to right, to the bang “Start” IOBox is the fifth, including SystemFolder), well it takes a lot of time.
I’m asking this because TaskManager shows a slowly incrementing memory usage by vvvv (when loading RNA module—the “first four” simply make their 50/75 mb jump and everything then’s fine) and experimenting this way is a deep time-comsuming method, since I really never get sure if everything’s working properly.
I’ll post the automated solution (LFO + Framedelay + etc) if you give me a hint.
Ah! And maybe it’s possible to load separate pieces of module, too… no?
seperating those modules in time sounds like a good idea. would be worth a try. or at least calculating the RNA data after everything else could work, too. i didn’t test it yet. but since the RNA data is the heaviest in memory it needs, it could work.
For this purpose connecting all the Ready and Build pins in a chain would be the easyest way.
Or, for instant result, disconnect the mRNA DataFormation module. The intron and exon boundarys won’t be shown then, but it should work way better.
Debugging is painfull here, indeed :)I should include a smaller example data set, like for e coli bacteria or something.
So here’s my time-switch. It’s now set to 16.5 secs, as I found on my pc to be the best time to avoid, uhm, overlapping freezing states of vvvv - it is something less to say the truth, but this gives me a good threshold.
I simply left RMNA module as the last one.
It’s still a hard job, but now more affordable. I’ve added also an automatic bang to build the SlicedParticleMesh.
Renderer was up and running in about ten mins (screensaver told me!) on an Athlon 64X2 Dual, XP 32bit.
It’s a skipping and tilting experience, when looking at a particular gene, but who knows, maybe it’s possible to get some good results even here.
Cool thanks for working on this project!
It feels a bit faster and shows that DataFormationMRNA is responsible for most of the loading time. Of course, the LFO thing is not the optimal solution, but good step anyway.
I agree; but LFO was the fastest and easiest thing I was able to think, and I wanted to see my genes on screen ASAP!
So I think I’ll patch something using the other bunch of nodes, to create a readywise start.
Another thing: when I close the patch and then vvvv, Windows pops up a security issue message for Explorer, then kills the process. Have you experienced this?
i don’t know anything about the architecture of this device. but depending on the live data an interface plugin could be possible and then of course live visualization could be possible. This is definately something for a bigger project. Let me know if you start digging in this direction.
Note that there is a difference between DNA sequencing and RNA analysis.
Both using same technology but aiming to different fundamental questions: What is the DNA basepair sequence? and how much RNA is expressed in the cell? One sentence in the article describes that the device is capable of RNA analysis, too, but its main function seems to be DNA sequencing, which would look different when visualized in a sensefull way (dont know how).
Really really amazing work!
Me and my friend (who has a masters in bioinformatics) were talking about doing something like this once. Of course with other work to do we never really got to the point of realizing it
thank metrowave. woa didnt realize that this thread has 2.3k views. i can tell a little story what happend in the meantime.
I really have to make it open source again, you’re right. but last year i got a little paranoid because my brain was going through all the bad things that could happen if it would go in wrong hands.
another reason why I put it down was that I wanted to make a new and better version.
the new version is able to visualize all 24k genes and not just one chromosome.
i also implemented the HumanNet database which covers all known gene interactions… resulting in a lot of lines in between. next thing would have been implementing edge bundles as first seen by Holden et al. but i got a big damping after getting no funding…
however to get back to the scientists again I am right now starting the company science-interactive.com. check it out there is already 5k jpeg of the new version accessible.
hope to get projects over this and want to establish vvvvjs in dataviz.
give me some time to sort things and i’ll send it to you.
@tekcor, thanks for replying, I totally understand… I must say I think this project is the most elegant dataviz. using vvvv I’ve seen. I’m a researcher at Cambridge Uni. and seen lots of 3D data visualization, yours stand out. I know because it was your thesis you’ve put lots into it. You could make a workshop in the next Node festival! looking forward and excited to see the new version. BTW, good luck in your interactive science startup great idea, I’m an archigestural scientist myself ;)