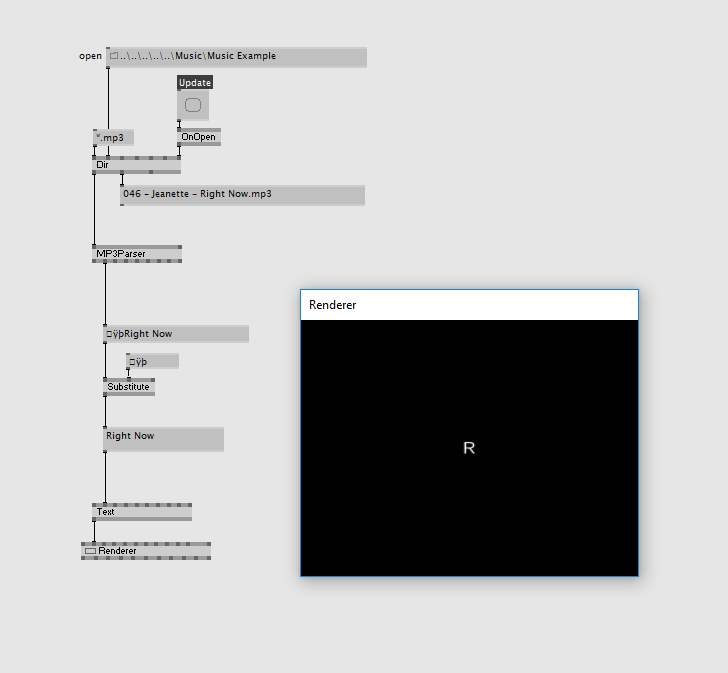
I have a question about Utf-16 in VVVV. I want to read out the Title of an MP3 File. So I used the MP3 Parser, but the Title Tag is shown in Utf-16 so there are always the symbols ÿþ in the beginning.
Have anyone an idea, how I can convert it to Utf-8 or another solution to fix the problem? I’ve tried to remove the first three symbols with the Substitute Node, but then you can see only the first letter and the rest is still missing.
but unfortunately, it doesn’t work in my patch. I tried to match a few other slices but there is no pair with the right result. Either there are only the symbols or nothing in the output.
When I try to do it like you, there is no result…
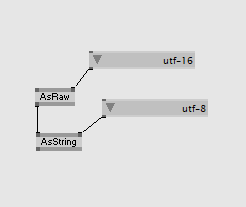
did you try the other way around? AsRaw with utf-8 or ASCII and then AsString with utf-16?
it could also be the case that it is the BOM (byte order mark), which some writers seem to store into the string sometimes. for the BOM the Substitute node should work because it is always at the beginning.
yes I tried it the other way around too, but then there are only chinese symbols. When I use the Substitute node, it seems to work in the directly output, but the renderer shows always only the first letter of the entire string.
i’m afraid this may as well be a bug in the node itself. it is a rather old/rarely used node that might have slipped through vvvv’s conversion to unicode. only with the .mp3s i have here i cannot reproduce the problem.
hello joreg,
thanks for your support.
I’m a vvvv newbie, so I’m not allowed to upload my patch, but here is a link. Maybe it would help you to reproduce and understand the issue.