I’ve actually solved this problem already, just documenting for others and if any VL gurus had a moment I wondered why it didn’t work the original way.
I’m trying to send a spread of UDP messages to the same destination.
Using Beta36
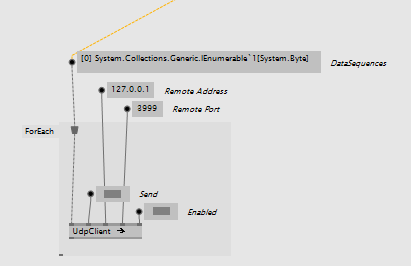
First I tried the obvious way using a UDPClient [IO.Socket] node inside a ForEach loop. It doesn’t work.
I was looking at this article
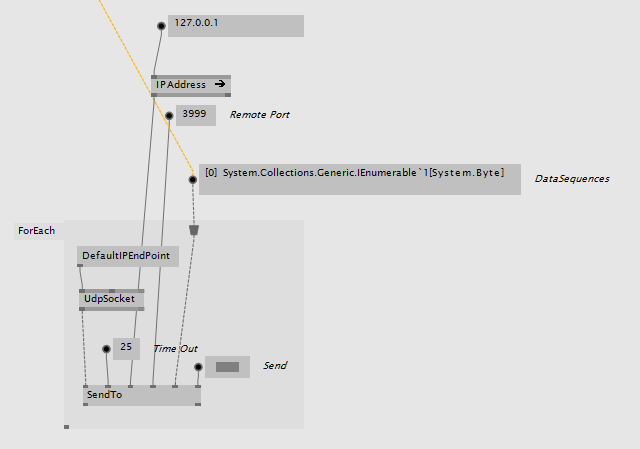
Using the SendTo node in the experimental lib I set it up like this which works.
Your screenshots look very weired to me - why couldn’t you just connect to the upstream pin directly? Why the need for the ForEach loop at all? I think you’ll need to show us the upstream part of your patch.
-The upstream pin was in an iobox just to label it.
-The ForEach loop is to send multiple separate UDP messages
(As opposed to multiple sequences of data in one UDP message)
Ah ok you have a spread of spread - well your initial example should work in my opinion. Did a little test locally and it works for me at least (UdpClient in a loop). Only difference I see is that you use the DefaultIPEndPoint node which means the socket opens on the localhost whereas the UdpClient uses Any as address for the socket - look inside and you’ll see what I mean.
To figure out what actually is going on and why your initial approach isn’t working I think you’ll have to send me a patch.
Hmm, you’re right. I just tested both methods with simpler data and they both worked. But the UDPClient mode still fails in a multiple send context when I feed it a bunch of byes.
Ups, sorry for late repsonse kind of missed your reply.
So indeed this is tricky and not obvious why first approach doesn’t work. Let me try to explain:
The loops in VL hold a seperate state for each slice. If the count of the loop increases a new slice with a new state gets created, if the count of the loop decreases those states get disposed of. In your case the count of your loop changes from zero to three once you press send, so in that frame three UDPClient states will get setup and each of them will try to send the data in background. But in the next frame the count of the loop goes back to zero, all the UDPClient states will now get disposed of and the already running send task in background will get cancelled → your data never makes it to the remote endpoint. If you keep the loop count at three by sending every frame you’ll see that it starts working as expected but that can’t be the solution of course.
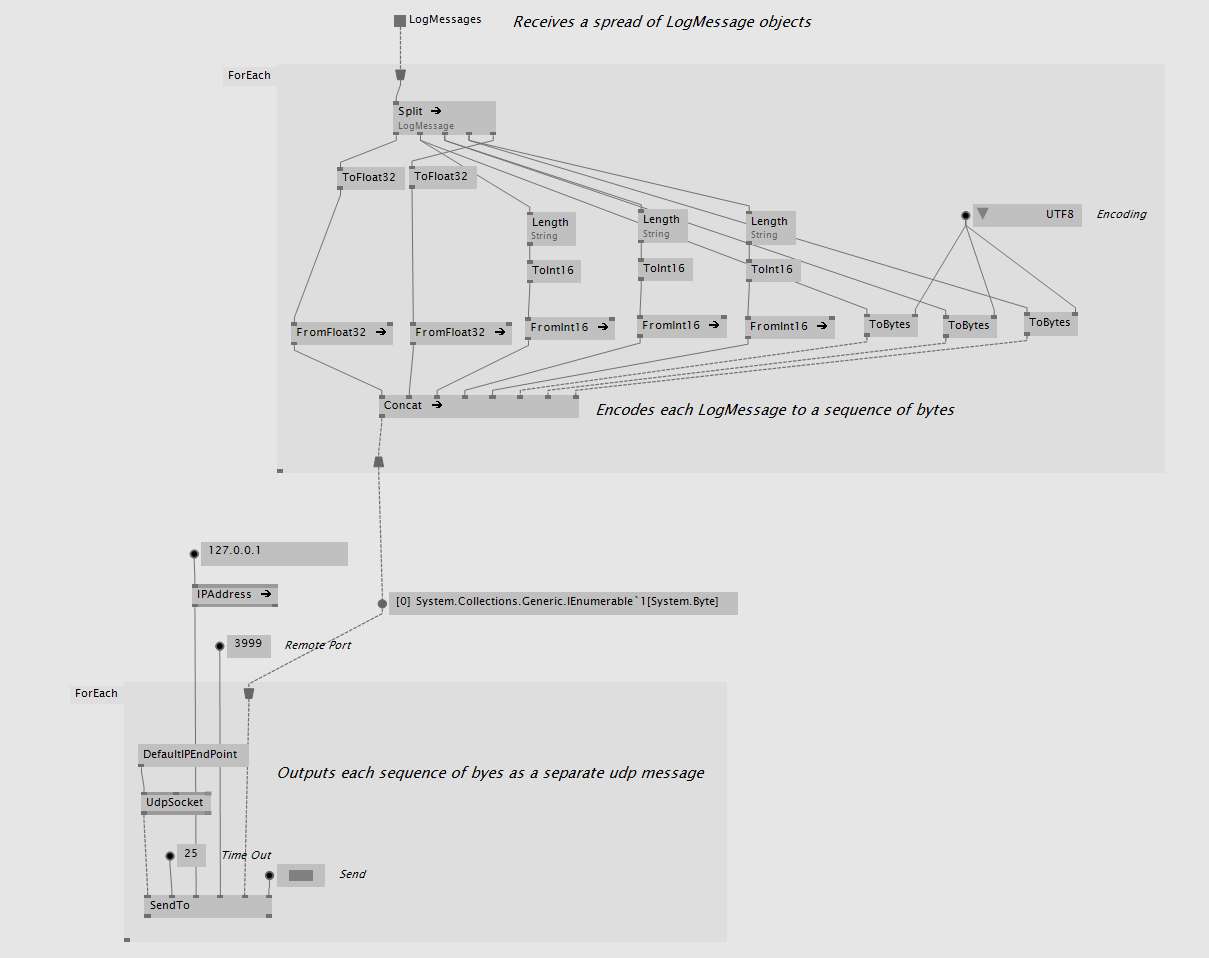
So we had another look at your patch and came to the conclusion that the most readable and efficient solution to your problem is using the UDPClient (Reactive) node which expects an observable of datagrams. In your foreach loop you build the datagrams and outside the loop you send all those datagrams to the UDPClient using a ToObservable (Sequence) node. See attached patch. UDP_Tester_2.zip (42.0 KB)
Thanks for your time with this.
That all makes sense, good to know I wasn’t going crazy.
Perhaps it would be possible in the future to have an error or warning when tasks are ‘auto cancelled’ in the background like this?
Or a way to tag that a node internally uses reactive tasks and you should be carefully not to implement it in contexts where it can be prematurely cancelled? (or that in these contexts you will need to manage the reactive programming more directly)
For a novice patcher that doesn’t understand async/reactive it could be quite confusing.