My previously posted question concerning grouping nearby values didn´t really do the trick in the end.
So I ask again, but with an adjustment:
Is there an easy way to find the nearest neighbours in just one 3D-spread?
I know, there are lots of nodes to find out the distance between TWO spreads, but how would I treat just one spread? I´m quite sure it’s quite easy, but I am totally stuck…
What I want to achieve is scaling up the slices proportional to their distance to the nearest neighbour.
The nearer, the bigger!
This sounds a little bit like the attractor nodes. Aren’t they what you are looking for? Or what would be different from an attractor?
if you only want to scale instead of displacing, measure the distance between the positions before and after the attractor and use that as a scaling factor…
I tried to use Attractor Self, which I supposed to be exactly what I was looking for, but when I attach the Position-Spread (it´s a Vector3), I only get a spread of NaN.
Using the Attractor and feeding the spread into both the inputs, it seems like the only slice taken into account for the attractor-position is the first.
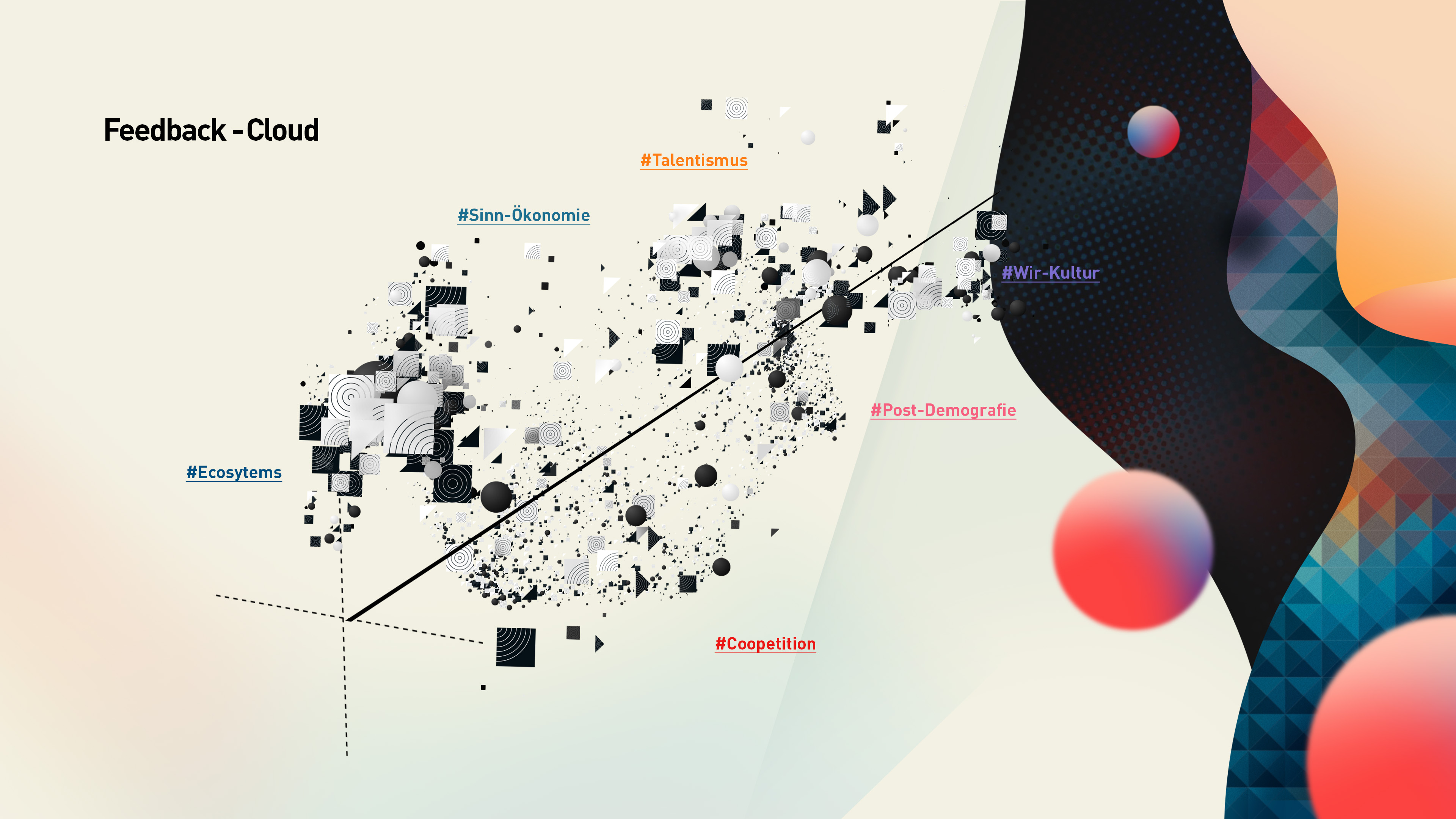
My task is to find accumulations of slices in a cloud of polling data and visualize them for better readability. Attractor is “kind of” what I am looking for. But I don´t know, how to remove the “kind of”.
My brain just doesn´t seem to get it :-D
It’s much better to do in VL, you do for each point and for each again for that point with every other point, then you can get your nearest neighbour where the lowest length and it isn’t 0 (since that is yourself)… and you do your processing…
You can do attractors but VL you will have much more control
@bjoern: the data come from a server I can´t actually share due to DSGVO-concerns. But it´s kinda simple stuff: you got two polling-questions with answers possible from 0-9 defining the position on x and y and a timetag for positioning on the z-axis (depth). Looks somewhat like this:
I expect some heavy clustering so I want to make it a bit more obvious, where those clusters are.
Actually I haven´t got much of an approach right now to be honest.
Just a day or two of research with no real solution, thus the question ;-)
I´ll give antokhios suggestion a try I guess.
I still got enough time to face my enemy and try to get into VL and its data-type madness I have a really hard time to understand (e.g. position != vector2 != spread)
There is one on parallel gpu if you prefer, you basically do a null draw with squared amount of calls, and then you intersect every point with every other point and discard all the inappropriate results… this type of stuff can be sorted with code without a hustle, but with nodes it’s a bit of pain