Hi, I need to read some scientific data, parse it (and display the result, let’s say as some moving dots).
The data is currently coming in the form of csv files. Each frame is one line in the file and consists of 5000 objects which in turn have 4 properties: PosX, PosY, FooA, FooB.
PosX/Y are string representations of floats, between 0.00000 and 0.99999. (I assume 5 decimal places are precise enough for my usecase since the screen has “only” a 4K resolution. )
FooA/B are string representations of single-digit ints (0-9). So one row consists of 20.000 values and looks like this basically:
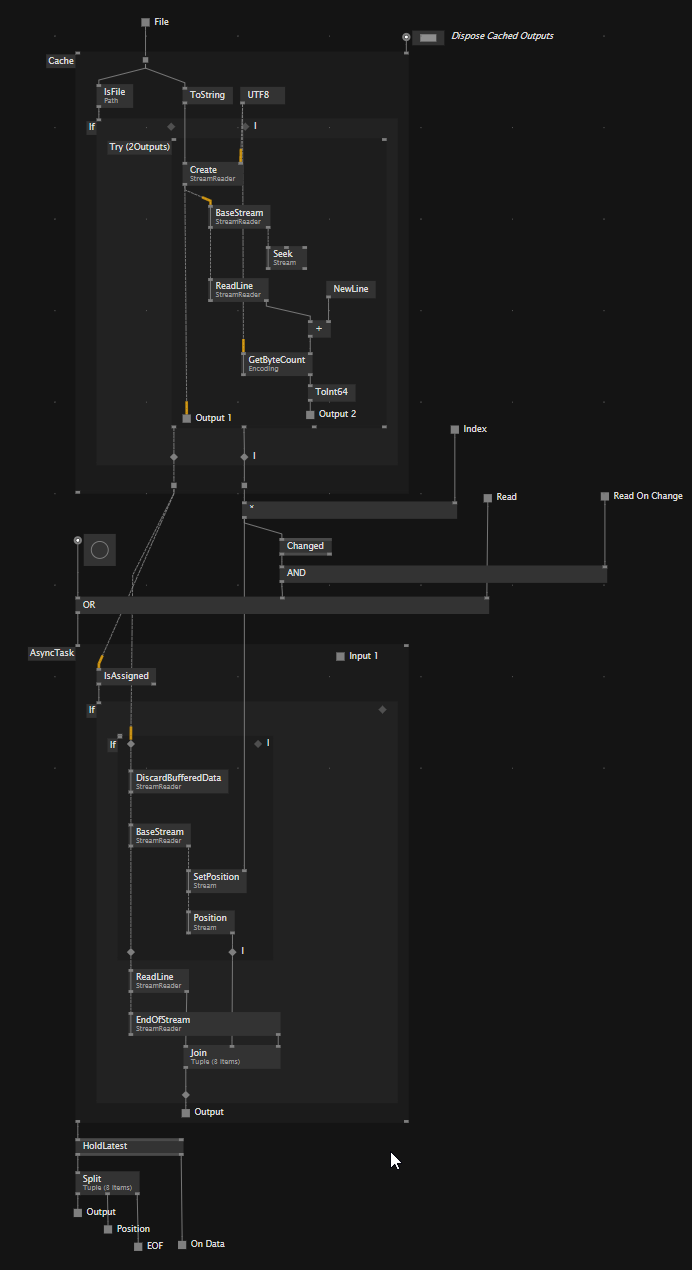
I know each line in one file will have exactly the same length. So I build a FileReader (LineWise)
that seeks to the correct position and reads the respective line/frame. This seems to be reasonably fast.
Then I use string.split() for splitting the line and then again a loop with some getspread / modulo logic and TryParse to “convert” the individual values to float → vector2 and int.
This is quite performance hungry and I am wondering if there maybe is a better/faster way.
For example I came accross the suggestion to use ReadOnlySpan:
Or this nuget:
I also thought about some kind of onetime NRT converter to some other format that is better suited for realtime playback, but so far I couldn’t come up with something nifty.
I don’t know the absolute length of the animation yet.
But most likely the files will become quite big and reading them all at once isn’t an option.
Also the granularity of the data and how fast it should be played back isn’t fixed yet.
But I think I’ll have to interpolate between two frames (lines). Not sure how to do this on the GPU. I guess I could have one buffer for Frame N and one for N+1 and then lerp between them using some kind of phase input, is this feasable?
In general not so confident about doing everything on the GPU, it’s not really my forte.
If that’s an XYZ data, you can write to image sequnce, and just lerp or blend as regular textures… The benefit is using streams without hassel, the downside preprocess everything
CSV readers in data science frameworks have had a lot of optimizations over the last decade, so its a shame they’re mainly based in python.
Obviously the hard part is handling so many columns. Creating an object with 5000-odd parameters doesn’t sound like a good way to spend your time. Here’s something [I haven’t tried]: CSVHelper, nuget here, which includes a Dynamic parser to an object of unknown rows if VL’s okay with it. If not maybe its a small c# plugin.
You maybe need a couple parses (collect the data, and maybe separate the floats from the ints)
If you can stick it in a Texture, sample the values linearly and readback the result that could be pretty performant. You can either get the Vec2s back or just the floats and use ValuesToVectors.
A similar idea could be implemented with OpenCV by creating an image from the values, stretching the image along the time line and sampling a row, though it’ll be a bit steppy.
It’s rather 5000 objects à 4 parameters and I also thought about putting them into (1D) textures one object per pixel (similar as proposed here). Then being able to play them back with a TexturePlayer and easily blend between them. But using one texture per row would lead to a massive amount of small files. Splitting multiple rows into multiple 2D Textures on the other hand will need some sophisticated playback logic…
According to the description it creates one object per row. I’d need multiple objects. Also while the amount of objects in one file is always the same, it will vary between files. I better should have said/written up to 5000.
And as far as I understood the whole file will be read at once which I think won’t be feasible.
I wondered if it’d be better/more performant to get rid of the decimal point for the floats parse them as ints and just divide them by 10^x afterwards.
I think if you want to optimise this you need to look on to memory stream or what’s so ever. E.g. you create buffer (resource in memory) then you write to that buffer from reader/readers spawned in background (not really sure how streaming memory pooled resource works)
Anyways not sure what’s the problem with 2d texture, you can map 1d index to 2d spread quite easy (I think buffer2tex, with formulas should be on vvorum)
The regular data processing pipeline: preprocess (sort, order, convert), write to cache, read cache
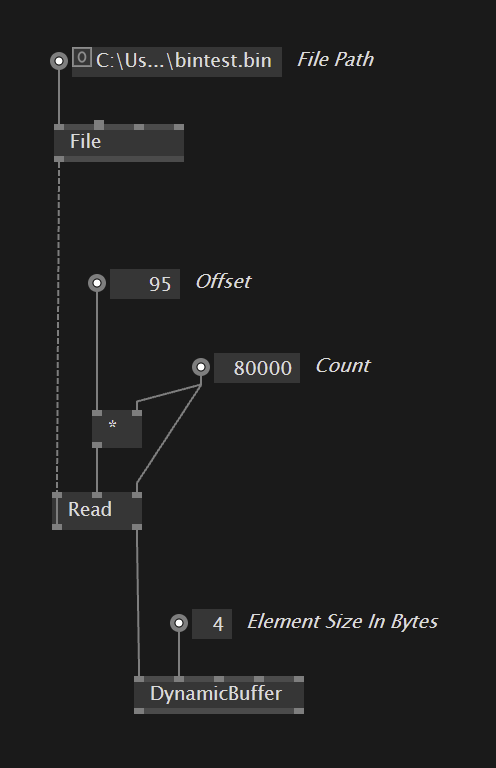
true, but you already have half of it with your reader. string parsing is always slow. i don’t think you want to waste your frametime with this. i’d try saving everything as floats. use GetFloat32Bytes on the values and save those. 20.000 floats per row, makes 80.000 bytes. you also save the FooA and FooB as floats because then you can pump them all into the gpu at once.
if i am not mistaken, then the reading could boil down to this:
note the Read node is experimental!
that is correct, all expensive operations that you can do offline, you should do to save frame time. string parsing is extremely slow and ordering, sorting is also not so fast.
so the data should be quickly accessible by a key or binary search. you could even have multiple versions of the data, depending on the use case.
but the first step would be to change strings into a binary format that can be ready directly into floats/ints/vectors…