i’d love to hear something from a dev or two on Vux’s original post.
sorry for the late reply about this, but as i already told you i’m not really into SIMD, so i thought i’d have a look at it and got a little confused now with the quoted statement.
what i read about SSE/SSE2/etc. was the addition of 8 or 16 new 128 bit registers, and a bunch of instructions, like adding 4 float32 (=128 bit) in one cycle or adding 2 double (=128 bit) in one cycle. so shouldn’t the data be 128 bit or 16 byte aligned?
so from my understanding switching to float one could add or multiply etc. twice as much values as with double in case of SIMD instructions. in case we talk about the FPU i don’t see any performance win in regard to computing speed, because the float or double is internally handled with a resolution of 80 bit. but of course it would need half as much memory, so there should be a marginal performance win possible.
in case of 3d, there’s not much to say. float would be the way to go.
switching to float would be easy, but before doing so we should seriously discuss in what kind of problems we might run into. anyone doing calculations dealing with very large and very small numbers? i mean there’s a big difference in the result in such a case.
Hey Elias,
Thought would give you a few details on sse.
You’re right on the side SSE adds new 128 bits registers, where you can perform the same instruction on multiple data at once. So in the case of doubles (64bits) you can process the same operation on two doubles at the same time, in the case of floats (not sure where this 80 bits comes from, as far as I know c/gpu floats are 32 bits, in delphi float it would be probably “Single” type ), you can process the same operation on 4 floats at a time.
So gain is far from marginal (3.5/4x for semi simple operations)
Also sse registers allows you a technique called shuffling, so you can reorder data within the same register (within one cycle).
This is extremely important for vector/matrix operations, as you can do operations like matrix/vector multiplication, cross/dot products without having your data leaving the registers at all, so you can process full operation without any memory load.
You can make really powerful cache friendly operations like that (accessing main memory costs more than 200 cycles for information). So potential gain if done well is really massive.
About alignment, indeed, it’s 16 bytes (not bits). So it’s just the fact that the starting memory location will be a multiple of 16. To load data in a SSE register it MUST be aligned (you can use _mm_loadu_ps to load unaligned, but it’s so slow you lose most of the benefit of it).
Now also to say SSE is good when you have a decent high spread count. When testing I generally find it more resilient than threading speed wise (more consistent execution time).
Of course it’s only one aspect of making things run fast (proper inlining, mod operator reduction, create constant buffers where you can, play with Commutativity on operators to name a few…), but all that makes it worthwhile at the end.
About the rounding error that’s right, floats are obviously more prone to some rounding errors than doubles (well you expect so having half the precision). Now for graphics it’s generally fine, for scientific computing I agree it can be pretty bad at times (depends on what you do of course).
On other features, control a node execution model at runtime (AutoEvaluate(On/Off), Disable Node), yes please!
And also nodes to be able to listen to mainloop events (Start/End Evaluate,Render…) would rock as well.
rifle cat is all for properly aligned floats!
@flateric:
thanks you for your most detailed explanation. it wasn’t my intention to downplay the obvious performance improvements when using SSE. vux already showed me some custom nodes he wrote, an the performance gain is indeed huge. what i wanted to point out, that (without considering the graphics pipeline now) by sticking with doubles it would also be possible to make use of SSE. so what i wanted to say that it’s not mandatory to switch to floats to make use of SSE. we could also gain a ~2x performance win with doubles, of course if using floats the win would be ~4x.
regarding the 80 bits: i was refering to the x87 instruction set:
quote:
By default, the x87 processors all use 80-bit double-extended precision internally (to allow for sustained precision over many calculations).
but it’s probably outdated and not relevant for modern cpus anymore.
now regarding the rounding errors:
i don’t think anyone uses vvvv for scientific calculations. therefor the performance gain introduced by switching to float outweights the increased rounding errors by far in my opinion. though the transistion would be an easy one from a programming point of view, one can not predict how older patches would behave, but i’d say, it’s worth a try!
seconded! :)
Just put a single/double switch on the front innit
Thanks for pointing the x87 bit, I generally code for x86 or x64 (which i need to look at more and more).
And I’m sure you didn’t wanted to downplay the effectiveness, you’re pretty right on it’s own using SSE on doubles could already be a good improvement (there’s a lot of other potential optimization techniques which easily apply to doubles too).
So you’re right, there’s already a very good potential for some high usage nodes (Operators, Damper (All animations), B-Spline, Vector join/split…)
And I also want to mention it’s definitely for some specific usages (if you use 20 quads with video and overlay, it’s definitely not gonna help for sure).
Now only problem is as long as you don’t do any geometry (or at most 2d), then sse on double is pretty fine, but as soon as you do geometry on 3d problem kicks in: you can’t fit a 3d/4d vector in a single register, so you lose all the shuffling capacity. (You can normalize a 3d/4d vector without moving your data from the register at all with float, it’s just not possible with doubles).
Same for matrices (even if it’s already as float in vvvv i’d explain the double case). You have 8 SSE registers, which means you can fit 32 floats, which is exactly 2 matrices (multiply in mind here ;)
@mrboni:
As much as a hidden float/double enum sounds a good idea, it’s not so simple development wise.
That means you have to duplicate your code for EVERY value/color node, which is “straightforward” if you use raw types (c# generics, c++ templates comes to help). But you would lose any possible optimization if you use sse (for reason mentioned above).
Not only on speed, having to deal with 2 types in same nodes would make code less clean -> leading to very likely less stable codebase as well.
So i would definitely prefer our favorite devvvvs to make one type work well than spend twice the time doing two types working half as good as they could.
Also I believe that would make patching much harder, as you have to choose a default type, so if you want the other one you have to switch for every node too.
wondering about 64 bit hehe :;]
compared to the huuuuge win of having aligned floats as datatype and sse/multithreading optimization on nodes dealing with these values the gain from moving to a full 64 bit codebase would be rather marginal imho as 64 bit code is not by any means faster in most standard scenarios. well, if you have to handle really big datasets the extended address range sure comes handy…
so i’m in no way against a move to 64 bit (i’m on 64 bit since xp64), but as explained above i think most users would benefit way more from other improvements. ;)
Just Created two custom datatypes for transform + color, so wanted to share some little benchmark on those types.
Transform uses the D3DMATRIXA16 structure instead of D3DMATRIX.
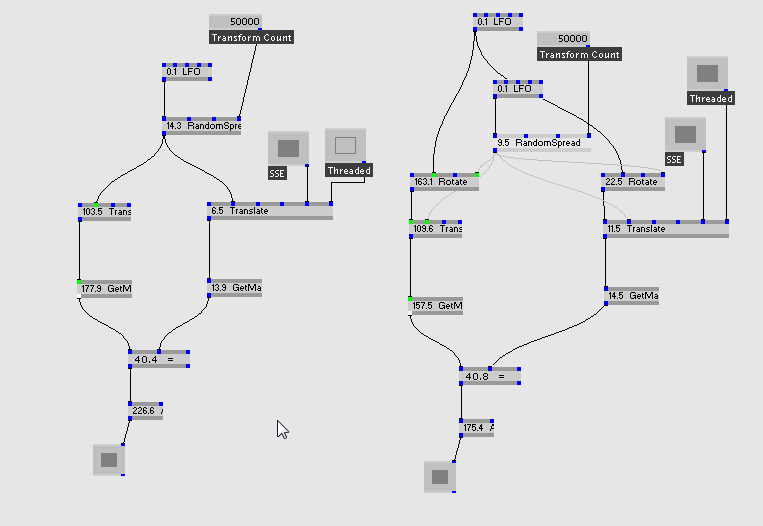
Color just uses __m128 (which is roughly 4 aligned floats, which fits perfectly in a single SSE register ;)

Couple of details on implementation:
-
RGB/Join Split nodes are just standard code with a toggle to enable/disable threading
-
Complement/Blend have both 2 options for Enable SSE and/or Threading
-
Translate have both threaded/sse toggle as well, it calls the dx function in “normal” mode, or just use inline sse code i wrote in sse mode (a hefty 4 lines :)
-
Transforms also have little optimization, if Transform input is not connected i just don’t use a default and write the matrix directly (saves a transform multiply), so i’ve put the bench in both cases (with/without transform in)
-
Most of them still use the standard value type for inputs (eg: double), so i still have to do the conversion, so perf should be a bit higher and code a lot cleaner ;)
As you can see we don’t speak of a 0.01% gain ;)
Will post some bench with Aligned Float value type next, stay tuned :)
this is impressive
yaaay, let’s revive this thread!
flaterics screenshots show that we’re talking ridiculously big performance gains here!
any comments from any devvvvs besides elias?
Yes, what’s the plan guys?
Optimized transform nodes would probably be the single most beneficial thing for most of my patching.
@velcrome: nothing much impressive, doing a simple transforms in sse is not so complex.here is the outrageous code for translate (that must have taken months ;)
buffer[i](i).d[0](0) = _mm_set_ps(0.0f ,0.0f,0.0f ,1.0f);
buffer[i](i).d[1](1) = _mm_set_ps(0.0f ,0.0f,1.0f ,0.0f);
buffer[i](i).d[2](2) = _mm_set_ps(0.0f ,1.0f,0.0f ,0.0f);
buffer[i](i).d[3](3) = _mm_set_ps(1.0f,(float)z[i % zcnt](i % zcnt),(float)y[i % ycnt](i % ycnt),(float)x[i % xcnt](i % xcnt));
@mrboni: same here, using transforms a hell of a lot.
Had a go with value stuff, created a sse float datatype and tested a few operators.
40000 random numbers spread addition:
- Native : 1.91 ms
- Using value type with Multi core (on i7) and some mod tricks: 0.29ms
- Single core SSE : 0.17ms
only way to have threaded double to beat single core sse was with spread count of 400000 (1.51ms double + thread, 1.6ms single core sse), but then multi core + sse was a mere 0.68ms ;)
Also tested normalize (3d Vector), since you can play with register shuffling: 10000 3d vectors:
- Native: 1.3ms
- SSE: 0.24ms
(Please note 1ms gain can look not a big gain, but when you want your visuals running at 60fps you have 16.6 milliseconds to have everything ready, so 1 ms is 6% or your render time, which is quite a lot for a single operator (since you obviously do other things).
Tested other things too, made a concept with some kind of “Stream” datatype and custom node interface (so you can have some subgraph processing outside of the mainloop), looks to get somewhere, more on that later ;)
+1 ;)
Nice bump ;) Disabling of nodes would be VERY helpful. There have been times when I have disabled unused quads, but to be able to turn off whole patches would be very nice indeed!
what’s the plan devs? and of course disable pin on every node.
I think Performances should be a serious priority at this stage of development.
In last few years we saw a wonderful improvement in GUI usability and many great new features (dynamic plugins,finder,…).
but now i really feel the limitations of the basement core of vvvv (eg nodes performance, dx engine limitations, …)
There should be like a balance between pushing features and updating core capabilities.
I’m telling this not just because of my needs, it’s also about the future of vvvv. I really believe that vvvv has a huge potential in so many fields of computer graphics. I spoke with many wonderful programmers/artists and many time the performance problem is one of the few things that make some people desist from switching to vvvv from other environments.
this is really a shame, vvvv can really be a kind of standard!
i’d like to hear from devvvvs if they have a plan (for the next future) about performance improvements in our belovvvved software.
I know the main problem is the time you can spend in development, that’s why getting involved some users like vux or flat eric (wich are interested and focused on this side of programming) maybe would speed it up and let you more free to concentrate on other features.
let me know what you think.
tnx :)
as always, the plan is to go ahead as planned.
we’ve focused on features recently, are alphatesting a stability release at
the moment and to complete the trinity of challenges very much value vuxens insights in this thread. still we have to do things step-by-step and the forum, while being a good place to collect ideas is not the place where we’ll discuss the further goings on.
so i hope you can all bear with us. high tides ahead…
i would propose we split this thread up,
avoid adding further feature requests
focus on finding consensus / educated decisions based on vux’s suggestions
biggest discussion points which require their own thread seem to be:
- use of float32 as replacement for Value / as base data type, SIMD optimisations
- threading individual nodes / the graph(?)
- streaming data outside of the main graph
but since this isn’t an open source project, we need to be more realistic about how much can be achieved from making lots of dev based conversations. so i’ll continue here
Concerning switching between double and float on pin:
It’s possible to template the classes in c++ to work on 2 different types
so you can write the same code and it’ll run on both types (at appropriate performance)
but it can a pain to debug / develop when there’s issues
and i’m not sure how well that’d translate across languages (c#, etc)
tbh, i’ve never come across an instance where i want to be using doubles in VVVV, i think the promise of ‘more accuracy’ might confuse users, as it’d only really be required for extreme cases (where devving plugins for double wouldn’t be much of a pain)
Float32’s
I still don’t get the float16 thing
I presume you meant float32 all along, but you’re talking about a type of float32 which will only ever start in a memory location that’s divisible by 2 bytes?I’m +1 for float32’s, they’re pretty much universally standard for graphics tasks, are internally quicker, quicker to interface with other types, and can be shipped wholesale to the GPU (as you’ve already mentioned)
SIMD optimisaton
This is something i’ve been playing with a bit (outside VVVV).
I was finding that my gcc code was running about 4x quicker than my VC++ code
it turns out that vc++ doesn’t support auto loop vectorisation (which is the good stuff in gcc which automatically uses SIMD for loops). and that the only way to use SIMD in vc++ is to write out what you want to do in terms of optimisation with Intrinsics (Microsofts own magic sauce).Are you using Intrinsics with your code vux?
Inheritance in types
+1
switching off evaluate for nodes (esp subpatches) is something I’ve been hankering for since my first month of using vvvv. glad to see it here!