I have a project that uses multiple VVVV instances.
For communication between them, I use ZeroMQ by @velcrome
ZeroMQ needs a conversion to Raw to send something.
So I start to convert my Values to Strings, then to Raw.
But the bad news is that the whole communication logic consumes more CPU than I save with my instances :(
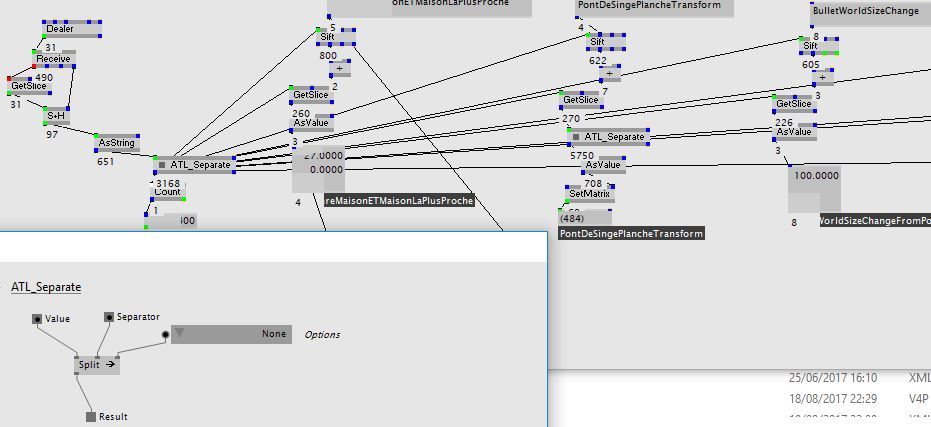
All Sifts, AsStrings, Getslices, Separates for encoding and decoding values and strings are very heavy.
In the end, I have 14000 ticks to decode only the position of my objects (thousands of objects)
So I guess I chose the wrong method!
I spent a lot of time searching through the forum in all the discussions mentioning VVVV instances, by @catweasel , @dottore .
So I wanted to know what are your strategies for instances communication?
VVVV-Messages? VL? A smarter use of AsStrings, Separates, Sifts…? OSC?
A cool thing would be to have all the S nodes of the instance encoded in one “object” as mentionned it that post :
@catweasel , you seem to use a lot of instances in your projects, for a long time, do you have any advice on this subject?
Are you sending a lot of data every frame? I try and minimise what gets sent between instances, so tweaks of parameters rather than big spreads to be calculated and then sent back, unless the idea is to have a small number coming back I guess. Big data, try and use the GPU, cs shaders and textures rather than instances if you can, and there are many cases you can’t, or see if joreg has a VL solution…
when sending data via network you want to pack data as quickly and small as possible. if you have values you should convert them to RAW directly, not via string.
so eg. if it is just a 3d-vector per object you’d best put them all in one spread then use AsRaw (Value) to convert that into the most compact representation. then AsValue (Raw) to get back the spread on the other end.
if the data per object you want to send is more complex than just a 3d-vector, you’d best create your object in VL and use the Serialize/Deserialize nodes to get them to/from RAW as quickly as possible. see the \girlpower\VL_Basiscs\DataStructure example for a start…
I use shared memory directly and where possible shared textures. If you have complex data, you can write your own simple dynamic plugins for the conversion. Lean mean and fast.
I tried the VL DataStructure example, but SerializeMyData and DeserializeMyData are too expansive when you feed them with many slices (e.g. >1000 RandomSpreads ).
So I tried to minimize the conversions, and I replaced the name of each value by BinSizes, and I have something pretty cheap compared to my previous patch.
if you only sync some random-seeds, you can produce the exact same spread on both instances… transfering thousands of values is not a good idea in most cases.
@sebl, the patchs with randomSpreads are just here as simple examples.
I need to use instances for heavy CPU tasks.
Often, I need them for VR patchs: OpenVR itself eats a big part of one CPU.
So I try to move everything that uses CPU in other instances.
But to be honest, for the moment I don’t gain a lot of performances with these techniques, and I barely reach a little 30/45 fps, after days spent doing various optimisation tricks.
You could use OSC send everytime you need it somewhere, and OSC receive on the other instance, just like send/receive (R/S).
OSC Encoder/ Decoder are not doing much cpu work when data isn’t changing. Also if you are creating 1000 or more object position you should use Noodles as it computes data in GPU. Don’t waste your time working with two vvvv instances, you won’t get much benefits out of this method. VVVV is a CPU killer anyway, and both instance will influence each other framerate…
@ludnny i am asking to elaborate on your CPU heavy tasks, because
is not entirely true anymore since vvvv can now use multiple cpus via vl. this will not work for all scenarios yet, but let’s hear what you got and we may be able to show you how to make use of this new feature.
a lot of little subpatchs, with little nodes, like Separate, Unzip, Cons, Sift…
Everything together, or encapsulated in subpatchs that are spreaded, it grows fast in the CPU…
some medium nodes like Bullet nodes, or Line Dx11…