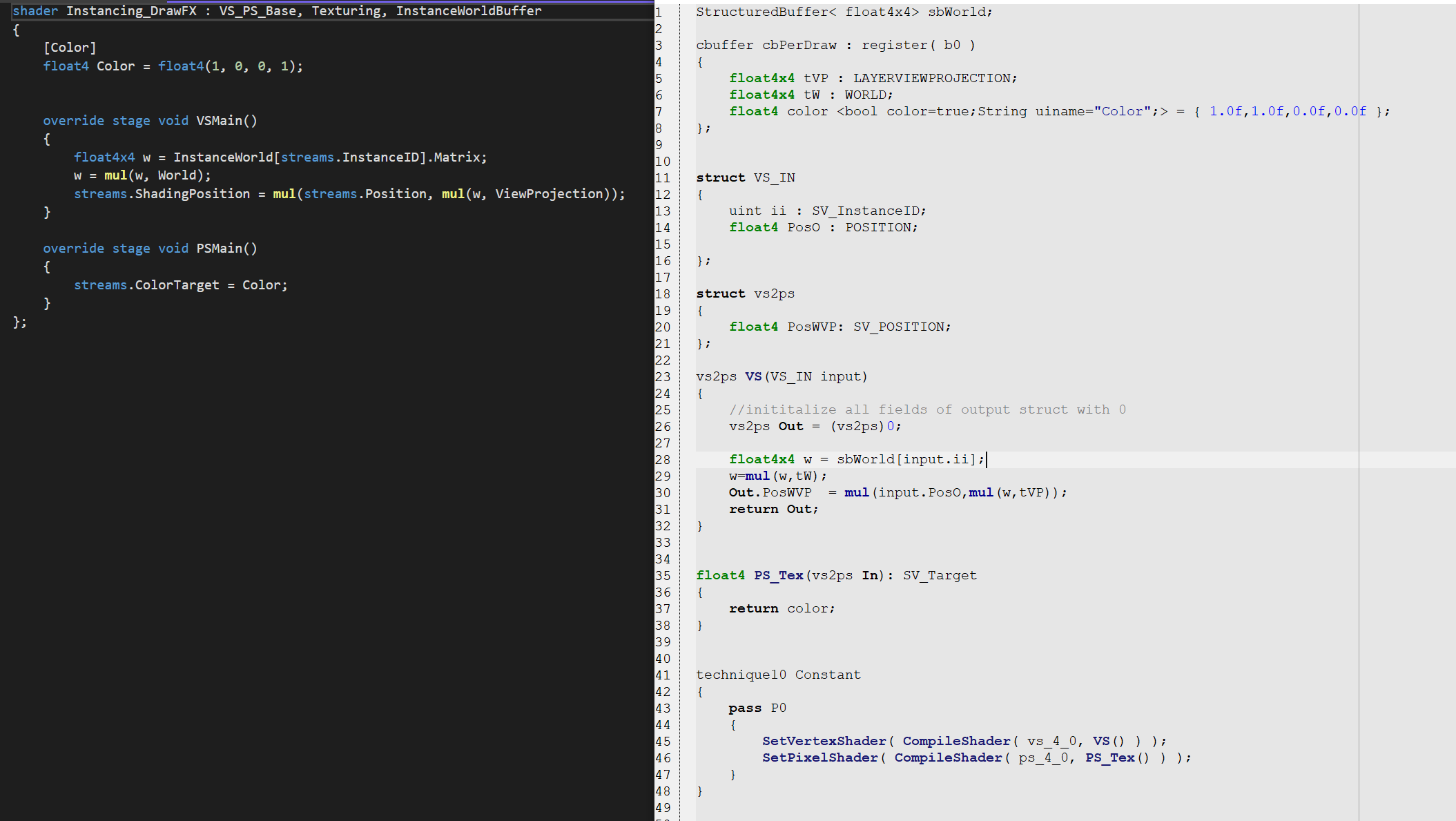
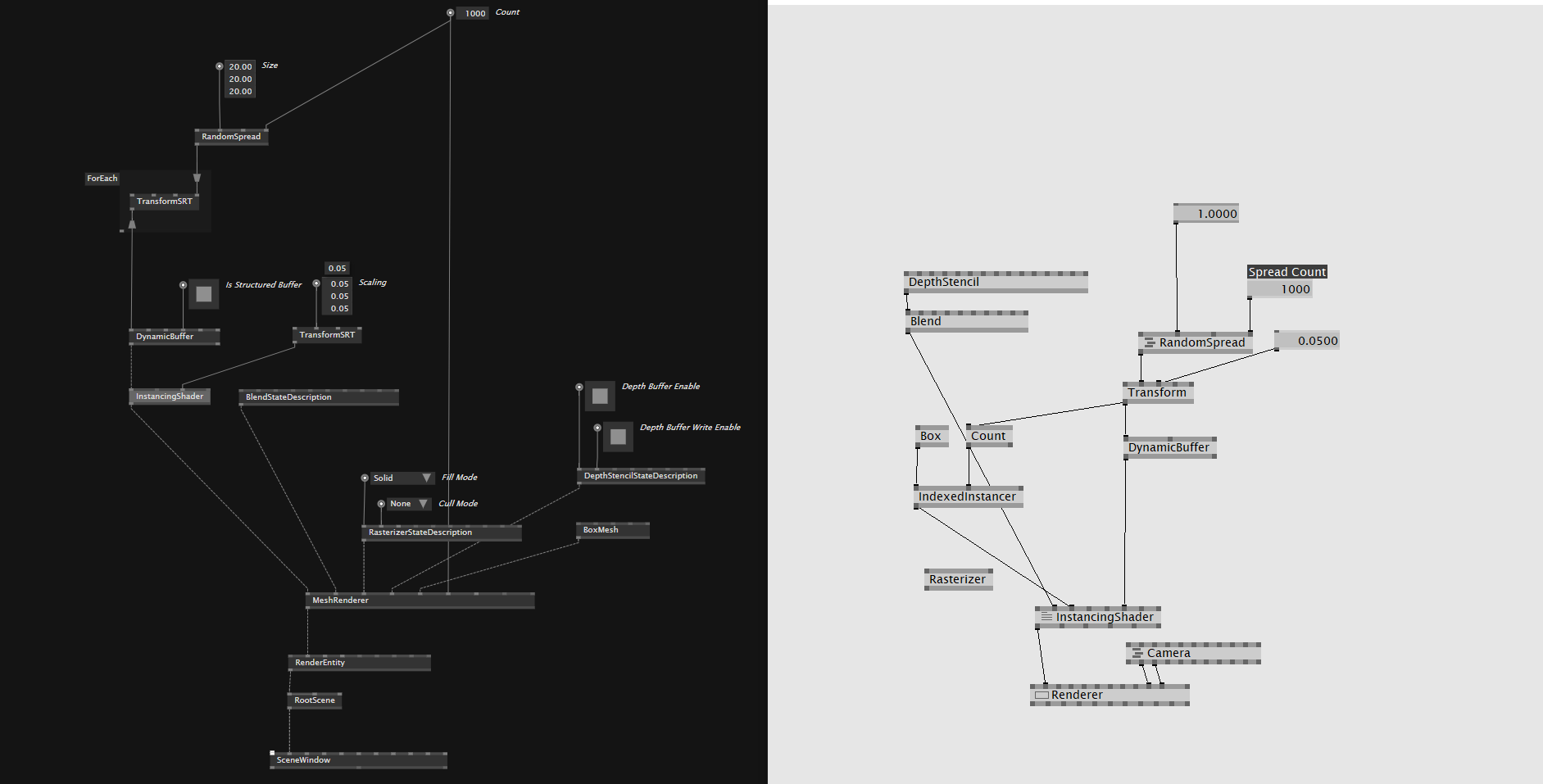
To compare the code paths more equally, make sure you use RenderWindow instead of SceneWindow and set the instancing count to a very high number, at least 10k, and make sure all matrices change in every frame.
And yes, you have to export the gamma patch to avoid other overhead.
You can also look into the Stride profiler to see how much time the actual draw call is using. And I believe in beta dx11 there is a query for the draw call time too.
the beta Renderer has no depth buffer set, you need to enable that in the inspector. and the pixel shader seems to take more time than the vertex shader in this simple patch, so window size matters a lot.
if I set them to the same size on my 4k screen, they both use exactly the same GPU resources with 100k objects, about 7% on my RTX 3070 mobile.
every other outcome would be quite strange since they both use DX11 as the backend, have the same shader, and do the same draw calls.
the only differences are on the CPU, where beta is faster as it doesn’t allocate memory for the large spreads in every frame, if you use an allocation-free approach in gamma, it is the same CPU utilization too, about 12% on my laptop with 100k objects…
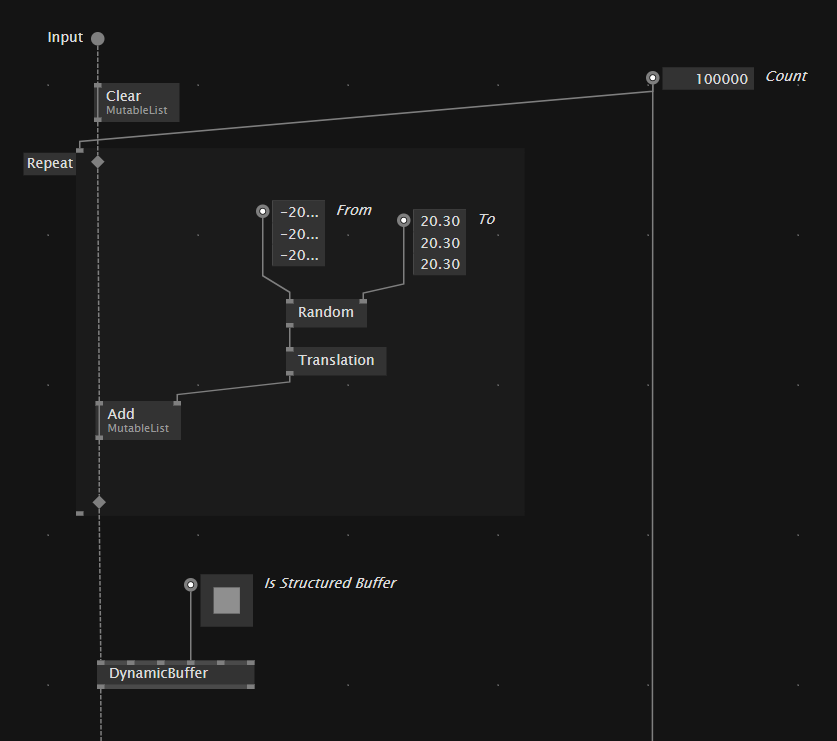
Unfortunately output splicers and the spread generator nodes both allocate new memory when animated. you won’t notice with lower spread counts but at 100k it is quite heavy, having gen2 collections every few frames which block the main loop.
it also uses the Translation node which doesn’t do any trigonometry for rotations and no matrix multiplications.
the patch above avoids both and re-uses the memory of a MutableList which doesn’t get downsized by the .NET runtime when you clear it.