Hello,
a simple question:
is a Compute Shader spreadable? How?
I see that dynamic buffers can be put toghether with Cons for dynamic buffers. If I simply put a spread of dynamic buffers in a CS this will not automatically spread.
I think this is a hard subject but maybe not.
If I have to process different spreads of datas with the same CS, how can I do it?
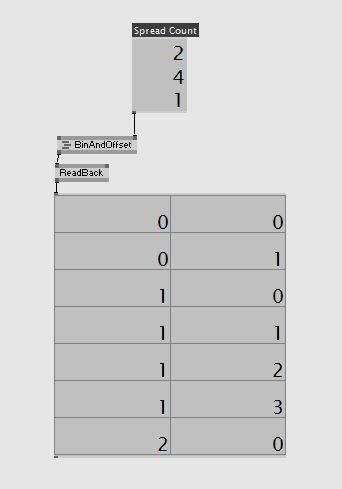
not a true spread, but a bin size solution, I’m working on it.
Is very specific to my implementation but if it works I will share the result, is also part of a bezier grafic implementation, sorry but I will share at the end of the work
Anyone has an idea how to do this? Been writing some of the spread generator nodes as compute shaders- to get basic function is pretty straight forward, but variable spread counts is another matter entirely…
A couple not so great things I’ve tried:
Uniform spread counts. You can keep everything on the gpu really easily then, but not really the desired result: in this case the spreads parameters are easily spreadable, but the spreadcount is not.
Calculate indices and bin ID on cpu & upload to gpu. This makes having variable spreadcounts ok, but has the downside of impacting performance any time the spreadcounts change
lol Kyle changing spreadcounts are anti-buffer concept, since u have to recreate resource every time u change amount of data. Buffers concept is u allocate more then enough memory once then write it once on cpu then process and read on GPU discarding undesired slices, i’m not totally sure if that statement is fully true, a lot depends on the case and a correct selection of buffer…
I know what you mean. But I still think GPU solution is not too hard and might be more desirable in some cases. Like in the 2nd hack above, you are making a lookup table basically, so there is really a cpu slice per thread, not so pretty if you have a HUGE buffer. The dynamic buffer nodes are nice, if apply is not on it acts same as s&h (upstream not calculated) but yeah, still doing that with a really huge count would just make the patch crash imho
Just came up with this function as a proof of concept for general solution- takes a buffer of spreadcounts/binsizes & thread ID, gives back bin ID & offset.